 GoByeonghu's Blog
GoByeonghu's Blog
Processes and Threads: Concepts and Implementation Across Languages
A Comprehensive Guide to Understanding and Applying Processes and Threads in Different Programming Languages
프로세스(Process)
정의
- 컴퓨터에서 연속적으로 실행되고 있는 프로그램이다.
- 실행중인(메모리에 적재된) 프로그램
- 프로세스는 프로세스를 실행하기 위한 작업의 최소 단위인 테스크(Task)를 완료하기 위해서 자원(resources)가 필요
구조(Process Structure)
- Text Section : 실행가능한 코드를 저장하는 공간
- Data Section : 전역 변수를 저장하는 공간
- Heap Section : 프로그램 실행동안 동적으로 할당되는 변수가 저장되는 공간
- Stack Section : 함수가 실행되는 동안 지역변수가 저장되는 임시 공간, 대표적으로 함수 매개변수, 리턴 주소, 지역 변수 등이 포함
프로세스 제어 블록(Process Control Block, PCB)

- PCB는 프로세스에 관한 정보 블록
- 프로세스 식별자(Process ID)
- 프로세스 상태(Process State) : new, ready, running, waiting, terminated 상태 중 하나에 해당됨
- 프로그램 카운터(Program Counter) : 메모리의 다음 명령어 주소를 저장함
- CPU 레지스터(CPU registers) : IR(Instruction Register), DR(Data Register), PC(Program Counter)와 같은 저장공간이 포함됨
- CPU 스케줄링 정보(CPU-scheduling information) : 프로세스 실행 순서를 정하는 정보, 우선 순위, 최종 실행시각, CPU 점유시간 등
- 메모리 관리 정보(Memory-management information): 해당 프로세스의 주소 공간 등
- 통계 정보(Accounting Information) : 프로세스의 실행, 시간 제한, 실행 ID 등에 사용되는 CPU양의 정보
- 입/출력 상태 정보(I/O status information) : 프로세스에 할당된 입출력장치 목록, 열린 파일 목록 등
- 포인터 : 부모프로세스에 대한 포인터, 자식 프로세스에 대한 포인터, 프로세스가 위치한 메모리 주소에 대한 포인터, 할당된 자원에 대한 포인터 정보
프로세스 상태(Process State)
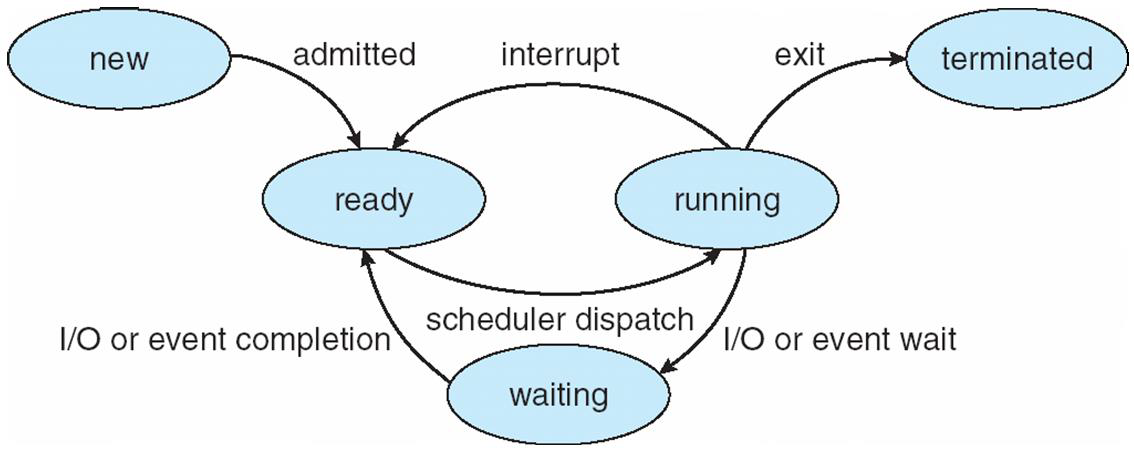
- New : 프로세스가 생성된 상태
- Running : 프로세스가 수행되는 상태
- Waiting : 프로세스 이벤트가 발생되어 입/출력 완료를 기다리는 상태
- Ready : 프로세스가 프로세서에 의해 실행되기를 기다리는 상태(언제라도 실행 가능)
- Terminated : 프로세스 실행 종료 상태
문맥 교환(Context Switch)
멀티프로세스 환경에서 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때 기존의 프로세스의 상태 또는 레지스터 값(Context)을 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값(Context)을 교체하는 작업
- 프로세스에서 문맥(Context)이란 마지막에 수행했던 명령어 위치이다.
- 프로세스의 문맥(Context)은 PCB에 표시된다.
- 인터럽트가 발생했을 때 운영체제는 현재 수행중인 프로세스의 문맥을 저장, 그리고 후에 다시 그 프로세스를 수행할 때 저장했던 문맥을 복구한다.
- Context Switch 정리
- CPU Core를 다른 프로세스에게 양도하는 것
- 현재 프로세스의 상태를 저장함
- Context Switch하게되면 다른 Process Context를 복원함
프로그램을 실행하다가 인터럽트 또는 시스템 콜이 발생하면 현재 프로세스의 상태를 PCB에 저장한다. 그리고 다른 프로세스를 수행하기 위해서 또 다른 PCB에서 문맥(상태)을 복원하여 수행
프로세스 스케줄링
정의
프로세스 스케줄링은 운영체제(OS)가 여러 프로세스를 어떻게 관리하고 실행할지를 결정하는 과정이다. 운영체제는 프로세스 상태(준비, 실행, 대기 등)를 기반으로 프로세스를 선택해 CPU를 할당하며, 다수의 프로세스를 효율적으로 관리하기 위해 다양한 스케줄링 알고리즘(FCFS, SJF, Round Robin 등)을 사용한다.
멀티프로그래밍(Multiprogramming)과 시분할 시스템(Time Sharing System)
1. 멀티프로그래밍 (Multiprogramming)
- 메모리에 여러 개의 프로그램을 동시에 적재하여 CPU가 항상 작업을 수행하도록 하는 방식이다. 주요 목적은 CPU의 유휴 시간을 줄이는 것이다.
- 한 프로그램이 I/O 작업을 수행하는 동안 다른 프로그램을 실행함으로써 CPU가 유휴 상태에 있지 않도록 한다.
- 각 프로그램은 메모리에 상주하면서 CPU의 실행을 기다린다. I/O 작업이 발생하면 CPU는 대기하지 않고 다른 프로그램을 실행한다.
- 예시:
- 기본적인 운영체제: 초기의 IBM OS/360 등은 한 번에 여러 작업을 메모리에 올려두고 I/O가 필요한 작업을 중지하며 다른 작업을 실행했다.
- 배치 처리 시스템: 여러 작업을 순서대로 실행하고 필요에 따라 전환하는 초기 배치 처리 환경.
2. 시분할 시스템 (Time-Sharing System)
- 여러 사용자가 동시에 CPU를 사용하는 것처럼 느끼도록 CPU 시간을 짧게 쪼개어 각 사용자 프로그램에 번갈아 할당하는 방식이다.
- 주요 목적은 응답 시간을 줄이고, 사용자들에게 인터랙티브한 환경을 제공하는 것이다.
- CPU 시간의 작은 조각(time slice)을 여러 프로그램에 차례로 할당하여, 사용자는 자신의 프로그램이 연속적으로 실행되는 것처럼 느낀다.
- 일반적으로 우선순위와 공정성을 고려하여 스케줄링된다.
- 예시:
- 유닉스 (Unix): 다중 사용자들이 동시에 접속하여 명령을 입력하고 응답을 받을 수 있도록 CPU 시간을 각 사용자에게 할당.
- 온라인 교육 시스템: 여러 사용자가 동시에 접속하여 학습 환경에서 즉각적인 피드백을 받도록 CPU와 네트워크 자원을 분배.
요약
| 항목 | 멀티프로그래밍 | 시분할 시스템 |
|---|---|---|
| 주요 목적 | CPU 유휴 시간 최소화 | 사용자 응답 시간 최소화 |
| 작동 방식 | I/O 발생 시 다른 프로그램 실행 | CPU 시간을 짧게 나누어 각 사용자에게 제공 |
| 사용 사례 | 배치 처리 시스템 | 인터랙티브 시스템 (예: 유닉스) |
| 느낌 | 프로그램이 비순차적으로 실행됨 | 사용자에게 연속적으로 실행되는 것처럼 보임 |
따라서 멀티프로그래밍은 CPU 자원 활용에 중점을 둔 방식이며, 시분할 시스템은 다중 사용자가 상호작용할 수 있도록 응답성을 중시한 방식이다.
프로세스 스케줄링 알고리즘 정의
프로세스 스케줄링 알고리즘은 CPU가 여러 프로세스를 효율적으로 처리할 수 있도록 프로세스에 CPU 시간을 할당하는 방법을 정의하는 알고리즘이다. 프로세스 스케줄링은 효율적인 자원 사용, 공정성, 빠른 응답 시간 등을 목적으로 하고, 다음과 같은 다양한 알고리즘이 사용된다.
선점 알고리즘 vs 비선점 알고리즘
| 특성 | 비선점 알고리즘 | 선점 알고리즘 |
|---|---|---|
| CPU 할당 중단 가능 여부 | 불가능 | 가능 |
| 응답 시간 | 긴 편 | 짧은 편 |
| 컨텍스트 스위칭 오버헤드 | 낮음 | 높음 |
| 구현 복잡도 | 낮음 | 높음 |
| 사용 사례 | 일괄 처리 시스템 | 다중 사용자, 실시간 시스템 |
- 비선점(Non-preemptive) 알고리즘
- 특징:
- 한 번 CPU를 할당받은 프로세스는 자신의 작업을 모두 마칠 때까지 CPU를 계속 사용한다.
- 다른 프로세스가 CPU를 강제로 빼앗을 수 없다.
- 대표적인 알고리즘:
- FCFS (First-Come, First-Served): 먼저 도착한 프로세스가 먼저 CPU를 할당받는다.
- SJF (Shortest Job First): CPU 시간이 가장 짧은 프로세스가 우선 할당된다.
- Priority Scheduling (우선순위 스케줄링) (비선점 방식): 우선순위가 높은 프로세스부터 CPU를 할당받는다.
- 장점:
- 알고리즘이 단순하고 구현이 쉽다.
- 프로세스가 CPU를 강제로 빼앗기지 않기 때문에 특정 작업을 보장할 수 있다.
- 단점:
- 응답 시간이 길어질 수 있다: CPU를 점유한 프로세스가 긴 작업을 수행 중일 경우, 다른 프로세스는 CPU 할당을 받을 때까지 대기해야 한다.
- 스타베이션(Starvation) 문제: 우선순위가 낮은 프로세스는 자주 대기하게 되어, 시스템에서 장시간 CPU를 할당받지 못할 수 있다.
- 선점(Preemptive) 알고리즘
- 특징:
- CPU를 할당받은 프로세스가 작업 중일 때라도, 우선순위가 높은 다른 프로세스가 도착하면 현재 프로세스의 CPU 사용을 중단하고 새로운 프로세스에 CPU를 할당한다.
- 특정 조건이나 우선순위에 따라 CPU를 빼앗아 재할당할 수 있다.
- 대표적인 알고리즘:
- Round Robin (RR): 각 프로세스는 정해진 시간(Time Quantum) 동안만 CPU를 점유하며, 시간이 지나면 다음 프로세스에 CPU가 할당된다.
- Priority Scheduling (선점 방식): 우선순위가 높은 프로세스가 도착하면 현재 프로세스를 중단하고 CPU를 할당받는다.
- SRTF (Shortest Remaining Time First): 남은 작업 시간이 가장 짧은 프로세스가 CPU를 점유하도록 한다.
- 장점:
- 응답 시간 단축: 중요한 프로세스가 빠르게 CPU를 할당받아 작업을 시작할 수 있다.
- 다중 사용자 환경에 유리: 여러 사용자가 동시에 프로세스를 실행해도 일정 시간마다 CPU가 돌아가며 할당된다.
- 단점:
- 오버헤드 발생: 프로세스 간의 전환 시 컨텍스트 스위칭이 발생하여 성능이 저하될 수 있다.
- 복잡한 구현: 우선순위 설정, 프로세스 대기 관리 등 복잡한 구조와 로직이 필요하다.
스케줄링 알고리즘
- FCFS (First-Come, First-Served)
- 설명: 먼저 도착한 프로세스부터 순서대로 CPU를 할당받는 비선점형 스케줄링 알고리즘.
- 특징:
- 구현이 간단하고, 큐에 도착한 순서대로 처리한다.
- 장기 작업이 먼저 도착하면 뒤의 짧은 작업들이 지연되는 Convoy Effect가 발생할 수 있다.
- 예시:
- 프로세스 A, B, C가 순서대로 도착할 경우 A가 완료된 후 B, 그 다음 C가 실행된다.
- 장점: 단순하고, 구현이 용이하다.
- 단점: 평균 대기 시간이 길어질 수 있고, 대기 중인 프로세스가 많을 때 성능이 저하된다.
- SJF (Shortest Job First)
- 설명: 가장 짧은 CPU 실행 시간을 요구하는 프로세스에게 먼저 CPU를 할당하는 알고리즘.
- 특징:
- 비선점형 방식에서는 CPU 요구 시간이 가장 짧은 작업을 우선 처리한다.
- 선점형 방식인 Shortest Remaining Time First (SRTF)는 남은 실행 시간이 짧은 프로세스를 계속 선택한다.
- 예시:
- 프로세스 A(10ms), B(5ms), C(2ms)가 준비 상태에 있다면 C, B, A 순서로 처리된다.
- 장점: 평균 대기 시간을 최소화한다.
- 단점: 프로세스의 실행 시간을 예측하기 어려울 수 있고, 긴 작업이 계속 지연될 수 있다 (Starvation 발생 가능).
- Priority Scheduling
- 설명: 우선순위가 높은 프로세스에게 CPU를 먼저 할당하는 스케줄링 알고리즘. 우선순위는 내부/외부 요인에 의해 결정된다.
- 특징:
- 선점형과 비선점형 방식 모두 가능하다.
- 우선순위가 낮은 프로세스는 무기한 대기하는 Starvation 문제가 발생할 수 있다.
- Aging 기법을 통해 우선순위가 낮은 프로세스의 우선순위를 점진적으로 높여 Starvation을 방지할 수 있다.
- 예시:
- A(우선순위 3), B(우선순위 1), C(우선순위 2) 프로세스가 있을 때, B, C, A 순서로 CPU가 할당된다.
- 장점: 중요한 작업을 우선 처리할 수 있다.
- 단점: 우선순위가 낮은 작업이 무기한 대기하는 문제 발생 가능.
- Round Robin (RR)
- 설명: 각 프로세스에 고정된 시간 할당량 (time quantum) 만큼 CPU를 할당하여 차례대로 실행하는 선점형 스케줄링 알고리즘.
- 특징:
- 주기적으로 모든 프로세스에 CPU가 할당되며, 시간 할당량이 만료되면 프로세스는 대기 큐의 끝으로 이동한다.
- 시간 할당량이 너무 길면 FCFS와 유사하게 동작하고, 너무 짧으면 오버헤드가 증가한다.
- 예시:
- A, B, C 프로세스가 있고 시간 할당량이 4ms라면 A(4ms), B(4ms), C(4ms) 순서로 할당된 후, 시간이 남은 프로세스가 다시 동일한 순서로 CPU를 할당받는다.
- 장점: 응답 시간이 짧고 공정하게 CPU를 분배한다.
- 단점: 시간 할당량의 크기에 따라 효율이 달라질 수 있다. 큰 작업이 여러 번에 나누어 처리되어 오버헤드가 증가할 수 있다.
- Multilevel Queue Scheduling
- 설명: 프로세스를 여러 개의 큐로 분류하여 각 큐에 다른 우선순위를 부여하고, 큐 간의 스케줄링과 큐 내부의 스케줄링을 병행하는 방식.
- 특징:
- 각 큐는 독립적인 스케줄링 알고리즘을 가질 수 있다 (예: 상위 큐는 Round Robin, 하위 큐는 FCFS).
- 일반적으로 사용자 인터페이스 프로세스, 시스템 프로세스 등 서로 다른 우선순위를 가진 프로세스들이 분리되어 배치된다.
- 예시:
- 상위 큐는 시스템 작업, 하위 큐는 사용자 작업에 사용되며, 상위 큐에 CPU가 우선 할당된다.
- 장점: 서로 다른 종류의 작업에 적절한 스케줄링을 적용할 수 있다.
- 단점: 큐 간의 유연한 이동이 어려워 특정 큐에 과부하가 생기면 비효율적일 수 있다.
- Multilevel Feedback Queue Scheduling
- 설명: 여러 개의 큐를 사용하며, 프로세스가 실행되는 동안 큐 간 이동이 가능한 방식. 시간이 지나면서 우선순위를 변경할 수 있는 유연한 구조를 제공한다.
- 특징:
- CPU를 많이 사용한 프로세스는 우선순위가 낮은 큐로 이동하고, 짧게 사용한 프로세스는 높은 우선순위 큐로 이동한다.
- 선점형 방식이며, 서로 다른 우선순위를 적용해 CPU 자원을 효율적으로 사용할 수 있다.
- 예시:
- A가 CPU를 오래 사용하면 하위 큐로 이동하고, 새로 진입한 B가 상위 큐에서 우선적으로 처리된다.
- 장점: 다양한 우선순위 작업을 처리할 수 있고, Starvation 문제가 상대적으로 적다.
- 단점: 알고리즘이 복잡하고 관리가 어려울 수 있다.
요약 비교
| 알고리즘 | 특징 | 장점 | 단점 |
|---|---|---|---|
| FCFS | 도착 순서대로 처리 | 구현이 간단 | Convoy Effect 발생 가능 |
| SJF | 짧은 작업을 우선 처리 | 평균 대기 시간 최소화 | Starvation 발생 가능 |
| Priority Scheduling | 우선순위 높은 작업을 우선 처리 | 중요한 작업을 우선적으로 처리 가능 | Starvation 발생 가능 |
| Round Robin | 일정한 시간 할당량을 순차적으로 분배 | 공정하게 CPU 분배, 짧은 응답 시간 | 할당량 설정이 효율에 영향 |
| Multilevel Queue | 여러 큐에 우선순위별로 배치 | 작업별로 다른 스케줄링 적용 가능 | 큐 간 과부하 시 비효율적일 수 있음 |
| Multilevel Feedback Queue | 큐 간 이동이 가능한 유연한 스케줄링 | 다양한 우선순위 작업 효율적 처리 가능 | 관리가 복잡하고 어려움 |
이와 같은 프로세스 스케줄링 알고리즘을 통해 운영체제는 프로세스의 요구에 맞게 효율적으로 CPU 자원을 분배하며, 시스템의 성능과 공정성을 향상시킨다.
CPU 스케줄링
정의
CPU 스케줄링은 프로세스들 중에서 실행될 프로세스를 CPU에 할당하는 구체적인 과정이다. 이때 OS는 준비 상태(Ready State)에 있는 프로세스들 중 하나를 선택하여 CPU에 할당하게 되는데, 이를 CPU 스케줄링이라고 한다.
CPU 스케줄링은 여러 프로세스가 CPU 자원을 효율적으로 사용할 수 있도록 프로세스에 CPU를 할당하는 운영체제의 주요 기능 중 하나이다. 운영체제는 동시에 실행되는 여러 프로세스가 있을 때 각 프로세스가 최대한 자원을 효율적으로 활용하면서도 공정하게 실행될 수 있도록 스케줄링 알고리즘을 사용해 CPU를 적절히 할당한다. CPU 스케줄링의 목표는 응답 시간, 대기 시간, 처리율, 공정성 등을 최적화하여 시스템 성능을 향상하는 데 있다.
CPU 스케줄링의 주요 개념
-
프로세스 상태: 프로세스는 생성, 준비, 실행, 대기, 종료 상태를 가질 수 있다. 준비 상태에 있는 프로세스들은 CPU 할당을 기다리고 있으며, CPU 스케줄러는 이들 프로세스 중 하나를 선택해 실행 상태로 전환시킨다.
- CPU 버스트와 I/O 버스트:
- CPU 버스트는 프로세스가 CPU를 사용하여 작업을 수행하는 시간이다.
- I/O 버스트는 프로세스가 I/O 장치 작업을 기다리는 시간이다.
- 대부분의 프로세스는 I/O 작업과 CPU 작업이 번갈아가며 발생하며, 이를 반영해 스케줄링이 이루어진다.
- 스케줄링 큐:
- 준비 큐(Ready Queue): CPU 할당을 기다리는 모든 프로세스가 대기하는 큐이다.
- 대기 큐(Device Queue): 특정 I/O 장치를 기다리는 프로세스들이 대기하는 큐이다.
- 스케줄러:
- 단기 스케줄러(CPU 스케줄러): 준비 큐에서 대기 중인 프로세스를 선택해 CPU에 할당하는 역할을 한다.
- 중기 스케줄러: 프로세스의 메모리 사용을 관리하기 위해 일시 중지, 다시 시작 등 작업을 수행한다.
- 장기 스케줄러: 시스템에 적절한 프로세스의 수를 유지하여 메모리와 CPU 자원 활용을 최적화한다.
CPU 스케줄링 알고리즘의 종류
- 비선점(Non-preemptive) 알고리즘:
- FCFS (First-Come, First-Served): 먼저 준비 큐에 들어온 프로세스에 우선순위를 주는 방식이다. 구현이 간단하지만, 응답 시간이 길어질 수 있고 대기 시간이 발생할 수 있다.
- SJF (Shortest Job First): CPU 요구 시간이 가장 짧은 프로세스부터 실행한다. 이 방식은 평균 대기 시간을 최소화하지만, 실행 시간이 긴 프로세스가 오랫동안 대기하게 될 수 있다.
- Priority Scheduling: 우선순위가 높은 프로세스를 먼저 처리하는 방식이다. 우선순위가 낮은 프로세스는 오래 기다리게 되어 스타베이션 문제가 발생할 수 있다.
- 선점(Preemptive) 알고리즘:
- Round Robin (RR): 각 프로세스는 정해진 시간 동안만 CPU를 사용하고, 타임 슬라이스가 끝나면 다음 프로세스에 CPU가 할당된다. 다중 사용자 시스템에 적합하며, 응답 시간이 짧아진다.
- Priority Scheduling: 우선순위가 높은 프로세스가 도착할 경우 현재 실행 중인 프로세스의 CPU 할당을 중단하고 새로운 프로세스에 CPU를 할당하는 방식이다.
- SRTF (Shortest Remaining Time First): 남은 작업 시간이 가장 짧은 프로세스가 우선순위를 갖는다. 새로운 프로세스가 더 짧은 남은 시간을 갖고 도착하면 현재 작업을 중단하고 새로운 프로세스를 실행한다.
CPU 스케줄링의 성능 평가 기준
- 처리량(Throughput): 일정 시간 동안 처리할 수 있는 프로세스의 수. 처리량이 높을수록 시스템 성능이 좋다.
- CPU 이용률(CPU Utilization): CPU가 작업을 수행하는 시간 비율. 일반적으로 CPU 이용률이 높을수록 시스템 성능이 향상된다.
- 응답 시간(Response Time): 준비 큐에 들어온 프로세스가 최초로 CPU를 할당받을 때까지 걸리는 시간. 응답 시간이 짧을수록 사용자 만족도가 높다.
- 대기 시간(Waiting Time): 준비 큐에서 프로세스가 CPU 할당을 기다리는 시간의 합. 대기 시간이 짧을수록 효율적이다.
- 반환 시간(Turnaround Time): 프로세스가 준비 큐에 들어온 후 종료될 때까지 걸리는 시간. 반응성이 높은 시스템일수록 반환 시간이 짧다.
CPU 스케줄링의 예시
- 웹 서버: Round Robin 알고리즘을 통해 다수의 클라이언트 요청을 빠르게 처리하여 짧은 응답 시간을 제공한다.
- 일괄 처리 시스템: FCFS 알고리즘을 사용하여 작업을 순차적으로 처리하며 응답 시간보다는 전체 처리량이 중요한 시스템에 적합하다.
- 실시간 시스템: 선점형 Priority Scheduling을 사용하여 중요한 작업이 발생할 때 빠르게 응답하도록 설계된다.
CPU 스케줄링은 시스템의 목적과 운영 방식에 따라 다른 알고리즘을 적용할 수 있으며, 각 알고리즘의 특징을 이해하고 시스템에 맞는 스케줄링을 선택하는 것이 중요하다.
프로세스간 통신 (Interprocess Communication, IPC)
프로세스는 상호 독립적이다. 즉, 메모리를 공유할 수 없다. 그렇다면 프로세스간에 데이토를 공유할때는 어떻게 해야하는가. IPC는 프로세스들간의 통신하는 방법을 의미한다.
1. 공유 메모리(shared memory)
메모리 위에 프로세스들간에 데이터를 공유할 수 있는 공유 메모리 영역을 사용하는 방법
2. 메시지 송수신(message passing)
메모리 위에 메시지 큐를 놓고 프로세스들이 전송할 데이터를 메시지 큐에 전송하고 프로세스들이 수신할 데이터를 메시지 큐를 통해 받는 방법
TO: IPC 딥다이브
스레드(Thread)
정의
쓰레드는 프로세스 내에서 Stack만 따로 할당 받고, 그 이외의 메모리 영역(Code, Data, Heap)영역을 공유하는 프로세스 내부의 분기된 흐름
프로세스와의 차이점
- 프로세스
- 완벽히 독립적이기 때문에 메모리 영역(Code, Data, Heap, Stack)을 다른 프로세스와 공유하지 않는다.
- 프로세스는 최소 1개의 쓰레드(메인 쓰레드)를 가지고 있다.
- 스레드
- 프로세스 내에서 Stack만 따로 할당 받고, 그 이외의 메모리 영역(Code, Data, Heap)영역을 공유
- 레드는 프로세스 내에 존재하며 프로세스가 할당받은 자원을 이용하여 실행
멀티 스레드
멀티쓰레딩(Multi-threading)은 하나의 프로세스 내에서 여러 스레드가 병렬로 작업을 수행하는 기법으로, CPU 자원을 효율적으로 사용하고 작업의 성능을 향상시킬 수 있다. 하지만 여러 스레드가 동시에 자원에 접근할 때 다양한 문제가 발생할 수 있으므로 주의가 필요하다.
특징
- 멀티 프로세스보다 적은 메모리 공간을 차지하고 문맥 전환이 빠르다
- 하나의 쓰레드에 문제가 생기면 전체 쓰레드가 영향을 받으며 동기화 문제도 있다
동시성과 병렬성
- 동시성
- 동시성은 멀티 작업을 위해 싱글 코어에서 여러 개의 쓰레드가 번갈아 실행하는 것
- 동시에 실행하는 것처럼 보이지만 사실은 번갈아가며 실행하고 있다.
- 병렬성
- 멀티 작업을 위해 멀티 코어에서 한 개 이상의 쓰레드를 포함하는 각 코어들을 동시에 실행하는 것
임계영역 (Critical Section)
- 설명: 임계영역은 여러 스레드가 동시에 접근하면 안 되는 코드 블록으로, 데이터를 보호하기 위해 상호 배제가 필요하다. 임계영역 내에서는 하나의 스레드만 실행되도록 보장해야 한다.
- 예시: 공유 변수나 데이터 구조를 수정하는 코드가 임계영역에 해당되며, 이를 보호하기 위해
mutex,lock등을 사용하여 동시 접근을 제한한다.
상호 배제 (Mutual Exclusion)
- 설명: 상호 배제는 동시에 여러 스레드가 하나의 자원에 접근하는 것을 방지하는 개념이다. 상호 배제를 통해 스레드가 임계영역에 진입할 때 다른 스레드가 동일 자원에 접근하지 못하게 제어할 수 있다.
- 예시:
lock이나mutex를 사용하여 특정 코드 블록을 보호하고, 자원에 대한 접근이 완료될 때까지 다른 스레드의 접근을 제한한다.
동기화 (Synchronization)
- 설명: 동기화는 여러 스레드가 데이터를 동시에 사용하거나 특정 시점에서 특정 작업이 수행되도록 일관성 있게 제어하는 것이다. 이를 통해 데이터의 무결성을 보장할 수 있다.
- 예시:
semaphore나condition variable을 사용해 스레드가 특정 상태나 이벤트에 맞춰 실행 순서를 제어한다.
동시성 문제 (Concurrency Issue)
- 정의: Concurrency Issue는 여러 스레드가 동시에 자원에 접근할 때 발생하는 일반적인 문제로, Race Condition과 Deadlock을 포함하는 개념이다. Race Condition과 Deadlock은 모두 동시성 문제의 사례라 할 수 있다.
- 설명: 동시성 문제는 여러 스레드가 동시에 자원에 접근할 때 발생하며, 예상치 못한 결과를 초래할 수 있다. 이는 변수나 데이터의 상태가 정확히 반영되지 않는 등 데이터 무결성에 영향을 준다.
- 예시: 한 스레드가 데이터를 읽고 있는 동안 다른 스레드가 데이터를 수정할 경우, 예기치 않은 결과가 발생할 수 있다.
- 동시성 문제로는 레이스 컨디션, 데드락이 있다.
1. 레이스 컨디션 (Race Condition)
- 설명: 레이스 컨디션은 두 개 이상의 스레드가 동시에 공유 자원에 접근하면서, 실행 순서에 따라 결과가 달라지는 현상이다. 이는 주로 예상치 못한 결과를 초래할 수 있다.
- 예시: 예를 들어, 두 스레드가 동시에 특정 변수 값을 읽고 수정하려고 할 때 발생할 수 있으며, 각 스레드가 변경을 완료하기 전에 다른 스레드가 접근해 잘못된 결과를 초래할 수 있다.
- 해결 방법: 상호 배제를 통해 임계영역을 보호함으로써 레이스 컨디션을 방지한다.
2. 교착 상태 (Deadlock)
- 설명: 교착 상태는 여러 스레드가 서로 다른 자원의 락을 기다리면서 무한히 대기하는 상황이다. 교착 상태는 시스템이 멈추는 심각한 문제를 초래한다. 두 스레드가 각각 서로의 락을 기다리면 데드락이 발생한다.
- 해결 방법: 교착 상태를 방지하려면 자원 할당의 순서를 정하거나
deadlock detection알고리즘을 사용하여 회피할 수 있다.
3. 라이블록 (Livelock)
- 정의: Livelock은 여러 스레드가 서로의 작업에 반응하면서 끝없이 상태가 변하지만, 실제로는 아무런 유효한 작업이 수행되지 않는 상태를 말한다. 즉, Deadlock처럼 진행이 멈추지만 차이점은 스레드들이 무언가 작업을 하고 있는 것처럼 보이지만 계속해서 서로 방해만 하고 있는 상태다.
- 예시: 두 사람이 복도를 지나가려고 할 때 서로를 피하려고 방향을 계속 바꿔, 서로 지나가지 못하고 계속 엇갈리는 상황을 생각할 수 있다.
4. 기아 상태 (Starvation)
- 정의: 기아 상태는 특정 스레드가 자원을 계속 요청하지만, 다른 스레드에 밀려 자원을 할당받지 못해 무한히 기다리게 되는 상황이다. 일반적으로 우선순위가 낮은 스레드가 고우선 순위 스레드에게 계속 밀려 발생한다.
- 예시: 우선순위가 높은 프로세스가 계속해서 CPU를 사용하고, 우선순위가 낮은 프로세스가 계속 대기하는 상황.
5. 리소스 경합 (Resource Contention)
- 정의: 여러 스레드가 동시에 같은 자원에 접근하려 할 때 발생하는 문제로, 자원 점유로 인해 성능이 저하되거나 프로그램의 효율성이 떨어지는 상황을 말한다. 주로 공유 자원에 대한 접근 순서나 자원 부족 문제로 발생한다.
- 예시: 두 개 이상의 스레드가 동시에 디스크, 메모리와 같은 하드웨어 자원을 사용하는 경우 성능 저하가 발생.
6. 우선순위 역전 (Priority Inversion)
- 정의: 우선순위가 낮은 스레드가 자원을 점유한 상태에서, 우선순위가 높은 스레드가 그 자원을 기다리느라 실행이 지연되는 상황을 말한다. 우선순위가 높은 스레드의 작업이 낮은 우선순위의 스레드로 인해 지연되는 문제.
- 예시: 실시간 시스템에서 중요한 작업이 낮은 우선순위 스레드 때문에 지연되는 상황.
7. 스레드 안전성 문제 (Thread Safety Issue)
- 정의: 여러 스레드가 동시에 자원에 접근할 때 공유 자원의 상태가 불안정해지고, 데이터가 의도치 않게 변경되거나 예상치 못한 결과가 발생하는 상황. 주로 적절한 동기화 기법이 적용되지 않을 때 발생.
- 예시: 두 스레드가 동시에 리스트에 데이터를 삽입하면서 데이터 일관성이 깨지는 경우.
멀티쓰레딩 문제 해결 방법
1. 상호배제(locking)
레이스 컨디션을 방지 할 수 있다. 자원의 동시 접근을 제어한다. 레이스 컨디션을 방지하기 위한 핵심 개념으로, 여러 스레드가 동시에 공유 자원에 접근하는 것을 방지하기 위해 “락(lock)”을 거는 행위로 이해할 수 있다.
- 뮤텍스 (Mutex)
- 설명: 뮤텍스는 상호 배제를 위해 사용되는 동기화 객체로, 단일 스레드만이 뮤텍스를 소유할 수 있다. 뮤텍스를 사용하여 보호할 자원에 대한 접근을 제어한다. 한 스레드가 뮤텍스를 잠그면 다른 스레드는 해당 뮤텍스가 해제될 때까지 대기한다.
- 사용 예: 공유 데이터 구조에 대한 접근 시, 뮤텍스를 사용하여 데이터 일관성을 유지한다.
- 세마포어 (Semaphore)
- 설명: 세마포어는 특정 자원에 접근할 수 있는 프로세스의 수를 제한하는 기법이다. 이진 세마포어는 뮤텍스와 유사하게 0 또는 1의 값을 가지며, 카운팅 세마포어는 정수 값을 가지며 여러 스레드가 동시에 자원에 접근할 수 있도록 한다.
- 사용 예: 리소스 풀에서 동시에 접근할 수 있는 스레드 수를 제한하는 데 사용된다.
- 모니터 (Monitor)
- 설명: 모니터는 공유 자원에 대한 접근을 제어하는 고수준 동기화 구조체이다. 모니터 내부에는 보호할 자원과 그 자원에 접근하기 위한 메소드가 포함되어 있다. 모니터는 자동으로 상호 배제를 보장한다.
- 사용 예: 생산자-소비자 문제와 같은 복잡한 동기화 문제를 해결하는 데 사용된다.
- 상태 플래그 (State Flags)
- 설명: 특정 상태를 플래그로 표시하여 다른 스레드가 자원에 접근할 수 있는지 여부를 결정하는 간단한 방법이다. 일반적으로 비트 플래그를 사용하여 사용 중인 자원과 대기 중인 자원을 구분한다.
- 사용 예: 단순한 자원 접근 제어에 사용되며, 구현이 간단하다.
- 대기열 (Queue)
- 설명: 대기열을 사용하여 자원에 접근하기 위해 대기하는 스레드를 순차적으로 처리하는 방법이다. 대기 중인 스레드는 대기열에 추가되며, 자원이 해제될 때 대기열에서 첫 번째 스레드가 자원에 접근한다.
- 사용 예: 여러 프로세스가 동일한 자원에 접근하려고 할 때 사용된다.
- 디스패처 (Dispatcher)
- 설명: 작업 큐를 관리하여 작업이 실행될 수 있도록 하는 기법이다. 우선순위에 따라 스레드를 선택하여 자원을 배정하며, 자원이 사용 중인 경우에는 다른 스레드를 대기 상태로 둔다.
- 사용 예: 실시간 시스템에서 작업의 우선순위를 관리할 때 사용된다.
2. 타임아웃 설정
데드락 회피를 위해, 락 대기 시 타임아웃을 설정하여 무한 대기 상태를 방지한다.
3. 교착 상태 회피 알고리즘
데드락 회피를 위해 자원 할당 시 순서에 맞게 요청하거나 순환 대기를 방지한다.
뮤텍스(Mutex)와 세마포어(Semaphore)의 차이
뮤텍스는 공유 자원에 대한 접근을 제어하기 위한 상호 배제 기법 중 하나로, Lock을 사용해 하나의 프로세스나 스레드를 단독으로 실행하게 한다.
반면에 세마포어는 동시에 접근 가능한 스레드의 개수를 지정할 수 있다. 세마포어 값이 1이면 뮤텍스와 동일한 역할을 하며, 값이 2 이상이면 동시에 접근 가능한 스레드 수를 제어한다.
- 세마포어의 변수: 공유 자원의 개수를 나타내는 변수
현재 수행 중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있다.
하지만 뮤텍스는 락(lock)을 획득한 프로세스가 반드시 그 락을 해제해야 한다.
- 이진 세마포어 (Binary Semaphore): 0과 1의 값만 갖는 세마포어로, 뮤텍스와 같다.
- 카운팅 세마포어 (Counting Semaphore): 도메인 제한이 없는 세마포어로, 0, 1 뿐만 아니라 2, 3, 4 등의 값들을 가질 수 있다.
멀티스레딩과 멀티프로세싱 비교
| 특성 | 멀티스레딩 (Multithreading) | 멀티프로세싱 (Multiprocessing) |
|---|---|---|
| 정의 | 하나의 프로세스 내에서 여러 스레드가 동시에 실행 | 여러 개의 프로세스가 동시에 실행 |
| 메모리 공유 | 스레드는 동일한 프로세스 메모리를 공유 | 각 프로세스는 독립적인 메모리 공간을 가짐 |
| 자원 사용 | 자원 사용이 효율적이며 오버헤드가 적음 | 각 프로세스는 메모리를 따로 할당받아 오버헤드가 높음 |
| 성능 | CPU 바운드 작업에서는 성능이 저하됨 | CPU 바운드 작업에서 성능이 향상됨 |
| GIL 영향 | Python의 GIL로 인해 CPU 바운드 작업에서 제약 | GIL의 영향을 받지 않음 |
| 응답성 | IO 바운드 작업에서 높은 응답성 제공 | 프로세스 간 통신이 필요할 수 있어 응답성이 낮음 |
| 에러 처리 | 스레드 간의 충돌로 인한 에러 발생 가능 | 프로세스 간 에러가 격리되어 발생 |
| 사용 예시 | 사용자 인터페이스(UI) 애플리케이션, 네트워크 서비스 | 데이터 처리, 계산 작업, 병렬 처리 |
하드웨어 관점의 프로세스와 스레드
CPU가 2코어 4스레드라면 다음과 같이 해석할 수 있다:
- 2코어:
- 이 CPU는 동시에 2개의 프로세스를 병렬 실행할 수 있다. 각 코어는 독립적으로 프로세스를 처리할 수 있는 처리 장치이기 때문이다.
- 4스레드:
- 하이퍼스레딩(Hyper-Threading) 기술이 적용되어 있다면, 각 코어는 2개의 스레드를 동시에 병렬 처리할 수 있다. 따라서, 2코어 4스레드의 CPU는 총 4개의 스레드를 동시에 실행할 수 있다.
이제 정리하자면:
- 동시에 2개의 프로세스를 병렬로 처리할 수 있으며,
- 동시에 4개의 스레드를 병렬로 처리할 수 있다.
하지만 실제로는 스레드 간의 실행이 코어의 자원을 공유하기 때문에, 성능이 절대적으로 두 배가 되는 것은 아니며, 각 스레드의 작업 부하와 CPU의 아키텍처에 따라 성능 차이가 있을 수 있다.
언어 별 멀티 스레드 전략
1. C++
- 스레드 라이브러리: C++11부터는
<thread>헤더를 통해 스레드를 생성하고 관리할 수 있는 표준 라이브러리를 제공한다. - 스레드 생성:
std::thread클래스를 사용하여 스레드를 생성할 수 있으며, 함수 포인터나 람다 표현식을 인자로 전달할 수 있다. - 상호 배제:
std::mutex,std::lock_guard,std::unique_lock등의 클래스를 통해 상호 배제를 구현한다. - 조건 변수:
std::condition_variable클래스를 사용하여 스레드 간의 통신 및 동기화를 관리할 수 있다. - 예시 코드:
#include <iostream> #include <thread> #include <mutex> std::mutex mtx; void print_message(int id) { std::lock_guard<std::mutex> lock(mtx); std::cout << "Thread " << id << " is running\n"; } int main() { std::thread threads[5]; for (int i = 0; i < 5; i++) { threads[i] = std::thread(print_message, i); } for (int i = 0; i < 5; i++) { threads[i].join(); } return 0; }
2. Java
- 스레드 클래스: Java는
Thread클래스를 통해 스레드를 생성할 수 있으며,Runnable인터페이스를 구현하여 스레드의 작업을 정의할 수 있다. - 상호 배제:
synchronized키워드를 사용하거나ReentrantLock클래스와 같은 고급 잠금 메커니즘을 사용하여 상호 배제를 구현할 수 있다. - 스레드 풀: Java는
Executor프레임워크를 통해 스레드 풀을 관리하고, 필요한 만큼의 스레드를 효율적으로 재사용할 수 있도록 지원한다. - 조건 변수:
wait(),notify(),notifyAll()메서드를 사용하여 스레드 간 통신을 처리한다. - 예시 코드:
class MyThread extends Thread { public void run() { System.out.println("Thread " + Thread.currentThread().getId() + " is running"); } } public class Main { public static void main(String[] args) { for (int i = 0; i < 5; i++) { MyThread thread = new MyThread(); thread.start(); } } }
3. Python
- 스레드 모듈: Python은
threading모듈을 통해 스레드를 생성하고 관리할 수 있으며,Thread클래스를 사용하여 스레드를 생성한다. - 상호 배제:
Lock,RLock,Semaphore와 같은 동기화 객체를 사용하여 상호 배제를 구현할 수 있다. - 전역 인터프리터 잠금(GIL): Python은 GIL로 인해 한 번에 하나의 스레드만 실행될 수 있으며, CPU 바운드 작업에는 스레드보다 프로세스 기반 병렬 처리인
multiprocessing모듈이 더 효과적일 수 있다. - 예시 코드:
import threading def thread_function(name): print(f"Thread {name} is running") if __name__ == "__main__": threads = [] for index in range(5): thread = threading.Thread(target=thread_function, args=(index,)) threads.append(thread) thread.start() for thread in threads: thread.join()