 GoByeonghu's Blog
GoByeonghu's Blog
개발자 인터뷰를 위한 CS 개념 정리
면접을 위한 CS 정리 문서
서론
본 문서는 IT직무의 인터뷰 대비를 위함과 동시에 전공자라면 익혀야하는 기초 CS지식에 대하여 정리한 문서이다. 자료구조, 알고리즘, 운영체제, SW공학(개발 방법론), 네트워크, 데이터베이스 등 6가지 과목에 집중하여 작성되었다.
자료구조
1. Graph (그래프)
정의
그래프는 정점(Vertex)과 간선(Edge)으로 구성된 데이터 구조로, 객체 간의 관계를 표현하는 데 사용된다. 정점은 그래프의 개체를 나타내며, 간선은 정점 간의 연결을 나타낸다.
특징
- 비순환성: 그래프는 방향 그래프(Directed Graph)와 무방향 그래프(Undirected Graph)로 나뉘며, 방향 그래프에서는 간선이 특정 방향을 가지지만, 무방향 그래프에서는 방향이 없다.
- 가중치: 그래프의 간선은 가중치를 가질 수 있어, 거리나 비용 등의 정보를 포함할 수 있다.
- 사이클: 그래프는 사이클이 있을 수 있으며, 이를 통해 복잡한 관계를 표현할 수 있다.
- 연결성: 그래프는 연결 그래프(Connected Graph)와 비연결 그래프(Disconnected Graph)로 나뉜다. 연결 그래프에서는 모든 정점이 연결되어 있으며, 비연결 그래프는 그렇지 않다.
정의상 포함관계
트리는 그래프의 특별한 형태로, 사이클이 없고 모든 정점이 연결된 상태를 가진다. 즉, 모든 트리는 그래프이지만, 모든 그래프가 트리는 아니다.
2. Tree (트리)
정의
트리는 그래프의 일종으로, 계층적 구조를 가지며 루트(root) 노드와 그에 연결된 자식 노드(child node)들로 구성된다. 트리는 사이클이 없으며, 각 노드는 최대 하나의 부모 노드를 가진다.
특징
- 계층 구조: 트리는 데이터의 계층적 구조를 표현하는 데 적합하다. 루트 노드에서 시작하여 각 노드는 자식 노드를 가질 수 있다.
- 노드 수: 트리에서 노드 수는 항상 부모 노드 수보다 하나 많다. 즉, 만약 트리에 n개의 노드가 있다면, n-1개의 간선이 존재한다.
- 높이: 트리의 높이는 루트 노드에서 가장 깊은 리프 노드까지의 거리로 정의된다. 트리의 높이가 작을수록 탐색과 삽입이 빠르다.
종류
- 이진 트리 (Binary Tree): 각 노드가 최대 두 개의 자식 노드를 가지는 트리. 노드는 왼쪽 자식과 오른쪽 자식으로 구분된다.
- 완전 이진 트리 (Complete Binary Tree): 마지막 레벨을 제외한 모든 레벨이 완전히 채워진 이진 트리.
- 포화 이진 트리 (Full Binary Tree): 모든 노드가 두 개의 자식 노드를 가지며, 리프 노드가 동일한 깊이를 가지는 트리.
- 이진 검색 트리 (BST, Binary Search Tree) : 이진 탐색 트리는 왼쪽 트리의 모든 값은 반드시 부모 노드보다 작아야 하고, 오른쪽 트리의 값은 부모 노드보다 큰 트리
- AVL 트리 (AVL Tree): 자기 균형 이진 탐색 트리로, 각 노드의 왼쪽 및 오른쪽 서브트리의 높이 차이가 1 이하인 트리.
- 레드-블랙 트리 (RBT, Red-Black Tree): 이진 탐색 트리의 변형으로, 각 노드가 빨간색 또는 검은색을 가지며 균형을 유지한다. BST가 삽입 순서에 따라 치우치는 형상을 방지하기 위해 등장했다. child가 없을 경우 child를 가리키는 포인터는 NIL 값을 저장한다. 이러한 NIL들을 leaf node로 간주한다.모든 노드를 빨간색 또는 검은색으로 색칠하며, 연결된 노드들은 색이 중복되지 않게한다.
- B 트리 (B Tree): 다수의 자식을 가지며 균형을 유지하는 자가 균형 다진 트리. B 트리는 데이터베이스와 파일 시스템에서 주로 사용된다.
- B+ 트리 (B+ Tree): B-트리의 변형으로, 모든 값이 리프 노드에만 저장되고, 내부 노드는 단순히 색인 역할을 한다. B+ 트리는 모든 리프 노드가 같은 레벨에 위치하므로 범위 쿼리 시 효율적이다.
3. Heap (힙)
정의
힙은 완전 이진 트리의 형태를 가지며, 부모 노드의 값이 자식 노드의 값보다 크거나 같아야 하는 최소 힙(Min Heap) 또는 작거나 같아야 하는 최대 힙(Max Heap)으로 구성된다. 힙은 주로 우선순위 큐를 구현하는 데 사용된다.
특징
- 완전 이진 트리: 힙은 항상 완전 이진 트리의 형태를 유지하여, 모든 노드는 최대 두 개의 자식 노드를 가진다.
- 우선순위: 최대 힙에서는 최대 값이 루트 노드에 위치하며, 최소 힙에서는 최소 값이 루트 노드에 위치한다.
- 시간 복잡도: 힙은 삽입, 삭제 및 우선순위 추출 작업을 O(log n) 시간 복잡도로 수행할 수 있다.
종류 및 시간복잡도
- 최대 힙 (Max Heap): 부모 노드의 값이 자식 노드의 값보다 크거나 같은 특성을 가진 힙. 최대 값이 루트 노드에 위치.
- 삽입: O(log n)
- 삭제: O(log n)
- 최대값 조회: O(1)
- 최소 힙 (Min Heap): 부모 노드의 값이 자식 노드의 값보다 작거나 같은 특성을 가진 힙. 최소 값이 루트 노드에 위치.
- 삽입: O(log n)
- 삭제: O(log n)
- 최소값 조회: O(1)
Hash
해시(Hash)는 임의의 크기를 가진 데이터를 고정된 크기의 해시 값으로 변환하는 과정 또는 그 결과 값을 의미한다. 해싱(Hashing)은 해시 함수를 사용하여 데이터를 매핑하는 방식으로, 주로 데이터 검색, 암호화, 데이터 무결성 검증 등 다양한 분야에서 사용된다. 해시 함수는 특정 입력에 대해 항상 같은 출력 값을 생성하도록 설계되며, 작은 입력 변화에도 전혀 다른 해시 값을 반환하는 특징이 있다.
해시 함수의 특징
- 고정된 크기 출력: 입력 데이터의 크기와 관계없이 해시 함수의 출력은 고정된 크기를 가진다. 예를 들어 SHA-256 해시 함수는 입력 크기와 무관하게 항상 256비트 크기의 해시 값을 생성한다.
- 결정적 성질: 동일한 입력 값이 주어지면 항상 동일한 해시 값을 반환해야 한다.
- 고속 처리: 해시 함수는 빠르게 계산될 수 있어야 한다. 특히 데이터 검색이나 암호화에서 빠른 속도를 요구한다.
- 충돌 저항성: 해시 함수는 서로 다른 두 입력이 같은 해시 값을 갖는 경우를 최대한 피해야 한다. 완벽한 충돌 저항성을 가지지는 않지만, 해시 충돌의 발생 확률을 최소화하는 것이 목표다.
- 역산 저항성: 해시 함수의 결과 값만으로 원래 입력 값을 추측하거나 복원하는 것이 불가능해야 한다.
해시의 활용
- 데이터 검색: 해시 테이블에서 데이터를 빠르게 검색하거나 저장하는 데 사용된다.
- 암호화: 데이터의 무결성을 확인하기 위해, 해시를 사용해 데이터의 변경 여부를 판별한다.
- 암호 해싱: 비밀번호 저장 시, 원본을 저장하는 대신 해시 값을 저장하여 보안을 강화한다.
- 디지털 서명: 데이터의 변경 여부를 확인할 수 있도록 해시 값으로 서명을 생성하여 위변조 방지를 한다.
Hash 충돌
해시 충돌(Hash Collision)이란 두 개의 서로 다른 입력 값이 동일한 해시 값을 가지는 경우를 말한다. 해시 함수는 고정된 크기의 해시 값을 반환하기 때문에, 무한한 입력 값을 고정된 크기의 해시 값으로 매핑하는 과정에서 충돌이 발생할 수밖에 없다.
충돌 문제의 원인
- 입력 공간 크기: 해시 함수는 입력 값의 크기가 무한할 수 있으나, 출력 값(해시 값)은 고정된 크기다. 따라서 필연적으로 일부 입력 값이 같은 해시 값을 가지게 되어 충돌이 발생할 가능성이 있다.
- 충돌 확률: 해시 함수의 출력 크기가 작을수록 충돌 확률은 높아진다. 예를 들어, 32비트 해시 함수는 2^32개의 고유한 값을 생성할 수 있지만, 더 많은 입력 값이 해싱될 경우 충돌이 발생할 수 있다.
충돌 해결 방법
해시 충돌이 발생할 경우 이를 해결하기 위해 여러 가지 방법을 사용할 수 있다.
- 체이닝 (Chaining)
- 충돌이 발생한 위치에 연결 리스트를 만들어, 동일한 해시 값을 가지는 데이터들을 그 리스트에 저장하는 방식이다.
- 검색할 때 해당 해시 값의 리스트를 순회하여 데이터를 찾는다.
- 장점: 해시 테이블의 크기를 동적으로 관리할 수 있다.
- 단점: 충돌이 많아질 경우 연결 리스트의 길이가 길어져 검색 속도가 느려질 수 있다.
- 개방 주소법 (Open Addressing)
- 데이터를 저장할 위치가 충돌하면 다른 빈 공간을 찾아 데이터를 저장하는 방식이다.
- 선형 탐사(Linear Probing): 충돌이 발생할 경우 일정한 간격으로 다음 위치를 탐색하여 데이터를 저장한다.
- 이중 해싱(Double Hashing): 해시 함수 두 개를 사용하여 충돌 시 두 번째 해시 함수를 이용해 다른 위치를 찾는다.
- 장점: 추가적인 데이터 구조가 필요하지 않다.
- 단점: 테이블이 꽉 차거나 연속된 빈 공간을 찾는 데 시간이 걸릴 수 있다.
- 재해싱 (Rehashing)
- 해시 테이블의 크기를 확장하고 새로운 해시 함수로 데이터를 다시 해싱하여 저장하는 방식이다.
- 장점: 충돌 문제를 줄이면서 성능을 유지할 수 있다.
- 단점: 해싱 작업을 다시 해야 하므로 비용이 발생할 수 있다.
충돌 저항성
암호학적 해시 함수의 경우 충돌 저항성(Collision Resistance)이 필수적이다. 충돌 저항성은 서로 다른 두 입력 값이 같은 해시 값을 생성하지 않도록 설계된 해시 함수의 특성이다. 일반 해시 함수와 달리 암호학적 해시 함수는 높은 충돌 저항성을 가지며, 이를 위해 해시 함수의 내부 구조가 복잡하게 설계된다. 예로, SHA-256, SHA-3 등의 암호학적 해시 함수는 충돌이 발생할 확률을 줄이기 위해 설계되었다.
해시는 데이터 검색, 암호화 등 다양한 응용에 필수적인 데이터 구조이다. 그러나 해시 충돌 문제를 해결하기 위해 체이닝, 개방 주소법, 재해싱 등의 기법을 통해 효율적으로 데이터를 관리하고 검색하는 것이 중요하다. 해시 충돌을 완벽히 방지할 수는 없지만, 충돌 확률을 최소화하고 효율적인 해시 구조를 설계하여 성능을 향상시킬 수 있다.
해시의 종류
해시는 컴퓨터 과학에서 데이터를 효율적으로 저장하고 검색하는 데 중요한 개념이다. 다양한 해시 기법은 데이터 무결성을 보장하거나 저장된 데이터를 빠르게 검색하는 데 유용하다. 이번 자료에서는 해시의 주요 개념인 해시 함수, 해시 테이블, 해시 맵을 비교하여 각 개념의 특징과 활용 방안을 깊이 있게 설명한다.
1. 해시 함수 (Hash Function)
해시 함수는 임의 길이의 입력 데이터를 고정된 길이의 해시 값으로 변환하는 알고리즘이다. 이는 데이터 무결성 검증, 암호화, 데이터 검색 최적화 등 다양한 용도로 활용된다.
해시 함수의 주요 특징
- 일방향성: 해시 함수는 단방향성을 갖는다. 즉, 주어진 해시 값으로 원래의 입력 데이터를 복원할 수 없다. 이는 보안성에 중요한 역할을 한다.
- 충돌 방지: 이상적인 해시 함수는 서로 다른 두 입력이 동일한 해시 값을 가지지 않도록 설계되어야 한다. 그러나 현실적으로 충돌이 발생할 수 있으며, 이를 최소화하는 것이 해시 함수 설계의 중요한 목표이다.
- 고정된 출력 길이: 해시 함수는 입력 데이터의 크기와 관계없이 항상 고정된 길이의 출력을 생성한다. 예를 들어, SHA-256은 입력 길이에 관계없이 항상 256비트(32바이트)의 해시 값을 생성한다.
- 민감성: 입력 값이 아주 조금만 변해도 해시 값이 크게 달라진다. 이를 눈사태 효과(Avalanche Effect)라고 하며, 보안성 향상에 기여한다.
해시 함수의 유형
- 암호학적 해시 함수: 보안이 중요한 경우에 사용된다. SHA-256, SHA-3, MD5 등이 있으며, 데이터 무결성 검증, 디지털 서명, 비밀번호 저장 등에 활용된다.
- 비암호학적 해시 함수: 속도가 중요한 경우에 사용된다. 대표적으로 MurmurHash, CityHash 등이 있으며, 해시 테이블의 키 생성, 데이터베이스 색인에 주로 사용된다.
해시 함수의 활용 사례
- 데이터 무결성 검증: 네트워크를 통해 전송된 데이터가 원본과 동일한지 확인하기 위해 해시 값을 비교한다.
- 디지털 서명: 해시 값과 서명을 결합해 데이터 위변조 여부를 확인한다.
- 비밀번호 저장: 비밀번호를 해시 값으로 변환해 저장하고, 인증 시 해시 값 비교로 비밀번호를 확인한다.
2. 해시 테이블 (Hash Table)
해시 테이블은 키-값 쌍을 저장하는 자료 구조로, 특정 키에 대해 해시 함수를 적용하여 해시 값에 해당하는 위치(버킷)에 데이터를 저장한다. 해시 테이블은 데이터 검색 속도가 매우 빠르며, 특정 키를 통한 검색이 평균적으로 O(1) 시간 복잡도를 갖는다.
해시 테이블의 주요 특징
- 버킷 구조: 해시 테이블은 해시 함수를 통해 생성된 해시 값을 버킷으로 매핑한다. 각 버킷은 특정 키-값 쌍이 저장되는 위치를 의미한다.
- 해시 충돌: 서로 다른 키가 동일한 해시 값을 갖게 되면 충돌이 발생한다. 해시 테이블은 충돌을 해결하기 위한 메커니즘이 필요하다.
- 충돌 해결 방식
- 체이닝(Chaining): 버킷이 링크드 리스트 등으로 연결되어, 동일한 해시 값을 갖는 여러 키-값 쌍을 같은 버킷에 연결해 저장한다.
- 개방 주소법(Open Addressing): 충돌 발생 시, 다른 빈 버킷에 데이터를 저장한다. 선형 탐색, 이차 탐색, 이중 해싱 등의 방식이 있다.
해시 테이블의 장단점
- 장점: 해시 함수를 통한 빠른 접근이 가능해, 데이터 검색 및 저장에서 높은 성능을 발휘한다. 특히 검색과 삽입의 시간 복잡도가 평균 O(1)이다.
- 단점: 해시 함수 설계나 충돌 해결 방식에 따라 성능이 크게 좌우된다. 잘못된 충돌 해결 방식 사용 시 성능이 급격히 저하될 수 있으며, 고르게 해시 값을 생성하지 못할 경우 버킷이 비대칭적으로 사용될 수 있다.
해시 테이블의 활용 사례
- 데이터베이스 색인: 데이터를 빠르게 찾기 위한 색인으로 사용된다.
- 캐시 시스템: 빠른 조회가 필요한 캐시 시스템에서 키-값 저장소로 활용된다.
- 딕셔너리 자료구조: 키-값 형태의 데이터를 저장하고 검색하는 데 사용된다.
3. 해시 맵 (Hash Map)
해시 맵은 해시 테이블과 유사하게 키-값 쌍을 저장하는 자료 구조이지만, 주로 비동기적 동작을 통해 효율성을 높인다. 해시 맵은 대부분의 프로그래밍 언어에서 딕셔너리 또는 연관 배열과 유사하게 동작한다.
해시 맵의 주요 특징
- 동기화 여부: 해시 맵은 기본적으로 비동기적이며, 다중 스레드 환경에서 동기화 처리가 따로 필요하다. 예를 들어, Java의
HashMap은 동기화를 지원하지 않아 다중 스레드 환경에서 데이터 일관성이 깨질 수 있다. - Null 허용 여부: 언어별로 다르지만, Java의 HashMap은 null 키와 null 값을 허용한다. 반면,
Hashtable은 null을 허용하지 않는다. - 성능: 동기화가 없기 때문에 단일 스레드 환경에서 해시 맵이 해시 테이블보다 빠르다. 그러나 다중 스레드 환경에서 동기화가 필요할 경우
ConcurrentHashMap과 같은 별도의 자료 구조를 사용하는 것이 좋다.
해시 맵의 장단점
- 장점: 동기화가 없기 때문에 단일 스레드 환경에서 빠르게 작동하며, 키-값 쌍 저장을 효율적으로 관리한다.
- 단점: 다중 스레드 환경에서는 동기화 처리가 없어 데이터 무결성이 깨질 수 있다. 이러한 경우에는 추가적인 동기화 처리가 필요하다.
해시 맵의 활용 사례
- 단일 스레드 애플리케이션: 동기화가 필요 없는 환경에서 데이터를 빠르게 검색하고 저장하는 데 유용하다.
- 메모리 캐싱: 캐싱에 활용해 자주 조회되는 데이터를 저장하고 빠르게 접근할 수 있도록 한다.
- 단순 딕셔너리 구현: 키-값 쌍으로 구성된 데이터를 저장하는 데 적합하다.
4. 해시 함수, 해시 테이블, 해시 맵의 비교 요약
| 개념 | 정의 | 주요 특징 | 사용 예시 |
|---|---|---|---|
| 해시 함수 | 데이터를 고정된 길이의 해시 값으로 변환 | 일방향성, 고정 길이 출력, 충돌 방지 | 데이터 무결성 검증, 비밀번호 보호 |
| 해시 테이블 | 해시 함수를 이용한 키-값 저장 자료 구조 | 버킷 구조, 충돌 해결(체이닝, 개방 주소법), 평균 O(1) 검색 속도 | 데이터베이스 색인, 캐시 시스템 |
| 해시 맵 | 비동기적 키-값 저장 자료 구조 | 동기화되지 않음, 단일 스레드에서 빠른 성능, 다중 스레드에서 동기화 필요 | 단일 스레드 애플리케이션, 메모리 캐싱 |
이 문서는 해시의 각 개념을 심층적으로 분석하고 비교하여 해시 함수, 해시 테이블, 해시 맵이 각각 어떤 상황에서 적합한지를 이해하도록 돕는다. 컴퓨터 과학 연구와 실제 개발 과정에서 각각의 해시 개념을 적재적소에 활용할 수 있어야 한다.
그 외 기본 자료구조 정리
- 배열 (Array) 배열은 동일한 데이터 타입의 요소들을 연속된 메모리 공간에 저장하는 자료구조이다. 인덱스를 이용해 빠르게 접근할 수 있으나, 크기를 변경할 수 없다.
- 시간 복잡도
- 접근: O(1)
- 검색: O(n)
- 삽입, 삭제: O(n) (특정 위치에서)
- 장점: 인덱스를 이용한 빠른 접근 속도
-
단점: 크기 고정, 특정 위치에서의 삽입과 삭제가 느림
- 예시: 정수 배열 [3, 5, 9]에서 인덱스 1의 값을 가져오려면 arr[1]을 사용하여 5에 접근한다.
- 연결 리스트 (Linked List)
연결 리스트는 각 노드가 데이터를 저장하고 다음 노드를 가리키는 포인터를 가지는 자료구조이다. 배열과 달리 크기를 동적으로 조절할 수 있다.
- 시간 복잡도
- 접근: O(n)
- 검색: O(n)
- 삽입, 삭제: O(1) (특정 위치에서)
- 장점: 크기 조절이 용이하며 삽입, 삭제가 빠름
-
단점: 인덱스 접근이 느리고 추가 메모리 사용
- 예시: 노드가 1 → 3 → 5로 연결된 연결 리스트에서 첫 번째 노드를 삭제하면 리스트는 3 → 5가 된다.
- 스택 (Stack)
스택은 LIFO(Last In, First Out) 방식으로 데이터를 처리하는 자료구조이다. 데이터의 삽입과 삭제는 한쪽 끝에서만 이루어진다.
- 시간 복잡도
- 접근: O(n)
- 검색: O(n)
- 삽입, 삭제: O(1)
- 장점: 순차적으로 데이터를 처리할 때 유리함
-
단점: 중간 데이터 접근이 어려움
- 예시: 함수 호출 시 스택 구조를 사용해 함수가 종료될 때마다 마지막 호출한 함수부터 복귀한다.
- 큐 (Queue)
큐는 FIFO(First In, First Out) 방식으로 데이터를 처리하는 자료구조이다. 데이터 삽입은 뒤에서, 삭제는 앞에서 이루어진다.
- 시간 복잡도
- 접근: O(n)
- 검색: O(n)
- 삽입, 삭제: O(1)
- 장점: 순차적으로 데이터를 처리할 때 유리함
-
단점: 중간 데이터 접근이 어려움
- 예시: 프린터 작업을 처리할 때 먼저 요청된 작업이 먼저 처리되는 방식이다.
- 해시 테이블 (Hash Table)
해시 테이블은 키-값 쌍을 저장하는 자료구조이다. 해시 함수를 사용해 키를 해시 값으로 변환하여 데이터를 저장한다.
- 시간 복잡도
- 접근: O(1) (평균), O(n) (최악)
- 검색: O(1) (평균), O(n) (최악)
- 삽입, 삭제: O(1) (평균), O(n) (최악)
- 장점: 빠른 데이터 접근 속도
-
단점: 해시 충돌 발생 시 성능 저하 가능
- 예시: 전화번호부에서 이름을 키로, 전화번호를 값으로 저장하여 이름을 통해 빠르게 검색할 수 있다.
- 트리 (Tree)
트리는 계층적 구조를 가지는 자료구조로, 노드들이 부모-자식 관계를 가진다. 이진 트리, AVL 트리, 힙 등 다양한 변형이 있다.
- 시간 복잡도 (이진 탐색 트리 기준)
- 접근: O(log n) (평균), O(n) (최악)
- 검색: O(log n) (평균), O(n) (최악)
- 삽입, 삭제: O(log n) (평균), O(n) (최악)
- 장점: 빠른 검색과 삽입이 가능
-
단점: 균형이 맞지 않으면 성능 저하
- 예시: 회사 조직도를 트리 구조로 표현할 수 있으며, 부모 노드는 팀장, 자식 노드는 팀원과 같은 관계를 나타낸다.
- 그래프 (Graph)
그래프는 정점과 간선으로 구성된 자료구조로, 정점 간의 관계를 나타낸다. 방향 그래프와 무방향 그래프가 있으며, 네트워크, 지도 등에서 자주 사용된다.
- 시간 복잡도 (인접 리스트로 구현 시)
- 접근: O(V + E)
- 검색: O(V + E)
- 삽입, 삭제: O(1) (인접 리스트 기준)
- 장점: 복잡한 관계를 표현할 수 있음
-
단점: 구현과 탐색이 어려움
- 예시: 친구 관계를 그래프로 표현할 수 있으며, 각 정점은 사람을, 간선은 친구 관계를 나타낸다.
- 맵 (Map)
맵은 키-값 쌍을 저장하는 자료구조로, 각 키는 고유하다. 주로 해시 테이블이나 트리 기반으로 구현되며 빠른 데이터 검색이 가능하다.
- 시간 복잡도
- 접근: O(log n) (트리 기반), O(1) (해시 기반, 평균)
- 검색: O(log n) (트리 기반), O(1) (해시 기반, 평균)
- 삽입, 삭제: O(log n) (트리 기반), O(1) (해시 기반, 평균)
- 장점: 고유한 키를 사용해 데이터를 빠르게 찾을 수 있음
-
단점: 메모리 사용량이 많을 수 있음
- 예시: 학생 ID를 키로, 성적을 값으로 저장해 특정 학생의 성적을 검색할 수 있다.
- 집합 (Set)
집합은 중복되지 않는 고유한 값을 저장하는 자료구조이다. 보통 값의 존재 여부를 빠르게 확인하기 위해 사용되며, 수학적 집합 연산을 지원한다.
- 시간 복잡도
- 접근: O(log n) (트리 기반), O(1) (해시 기반, 평균)
- 검색: O(log n) (트리 기반), O(1) (해시 기반, 평균)
- 삽입, 삭제: O(log n) (트리 기반), O(1) (해시 기반, 평균)
- 장점: 중복이 없는 데이터 관리에 적합하고, 빠른 검색 속도
-
단점: 삽입 순서 유지가 어려움 (일부 구현에서만 지원)
- 예시: 대회 참가자의 ID를 집합으로 저장하여 중복 없이 관리하고, 특정 ID가 이미 등록되었는지 확인할 수 있다.
각 자료구조는 데이터 특성과 활용 목적에 맞춰 선택해야 하며, 각기 다른 시간 복잡도와 장단점을 가진다.
데이터베이스
데이터베이스의 특징
- 실시간 접근성(Real-Time Accessibility) : 비정형적인 질의(조회)에 대하여 실시간 처리에 의한 응답이 가능해야 한다.
- 지속적인 변화(Continuous Evloution) : 데이터베이스의 상태는 동적이다. 즉 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)으로 항상 최신의 데이터를 유지해야 한다.
- 동시 공용(Concurrent Sharing) : 데이터베이스는 서로 다른 목적을 가진 여러 응용자들을 위한 것이므로 다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야 한다.
- 내용에 의한 참조(Content Reference) : 데이터베이스에 있는 데이터를 참조할 때 데이터 레코드의 주소나 위치에 의해서가 아니라 사용자가 요구하는 데이터 내용으로 찾는다.
데이터베이스 언어(DDL, DML, DCL)
- DDL (정의어 : Data Definition Language) : 데이터베이스 구조를 정의, 수정, 삭제하는 언어 ( alter, create, drop )
- DML (조작어 : Data Manipulation Language) : 데이터베이스내의 자료 검색, 삽입, 갱신, 삭제를 위한 언어 ( select, insert, update, delete )
- DCL (제어어 : Data Control Language) : 데이터에 대해 무결성 유지, 병행 수행 제어, 보호와 관리를 위한 언어 ( commit, rollback, grant, revoke )
정규화
이상현상
- 삽입 이상 : 자료를 삽입할 때 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 갱신 이상 : 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
- 삭제 이상 : 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
저장 프로시저
사용하고자 하는 Query에 미리 형식을 지정하는 것을 말한다. 지정된 형식의 데이터가 아니면 Query가 실행되지 않기 때문에 보안성이 크게 향상한다. SQL Injection 예방에 유리하다.
트랜젝션(Transaction)
Elastic Search
- 엘라스틱 서치는 동의어나 유의어를 활용한 검색이 가능하며, 비정형 데이터의 색인과 검색이 가능하고, 역색인 지원으로 매우 빠른 검색이 가능하다.
- MySQL 최신 버전에서 n-gram 기반의 Full-Text 검색을 지원하긴 하지만, 한글 검색의 경우 아직 미흡하다
- Full-Text : 이미지, CSS, 글 등의 복합적으로 이뤄진 컨텐츠에서 순수하게 텍스트만 추출한 데이터를 의미. 이 과정을 보통 크롤링으로 구현함 ( 엘라스틱 서치의 검색엔진엔 크롤러가 빠져있어 별도로 구축해야함)
옵티마이저(Optimizer)
- SQL을 가장 빠르고 효율적으로 수행할 최적의 처리 경로를 생성해주는 DBMS 내부의 핵심 엔진
- 여러가지 실행 계획을 세우고, 최고의 효율을 갖는 실행계획을 판별한 후 그 실행계획에 따라 쿼리를 수행하게된다.
Join
-
INNER JOIN: 서로 연관된 내용만 검색하는 조인 방법이다. A와 B에 대해 수행하는 것은, A와 B의 교집합을 말한다. 벤다이어그램으로 그렸을 때 교차되는 부분이다.
-
OUTER JOIN: 한 쪽에는 데이터가 있고 한 쪽에는 데이터가 없는 경우, 데이터가 있는 쪽의 내용을 전부 출력하는 방법이다. A와 B에 대해 수행하는 것은, A와 B의 합집합을 말한다. 벤다이어그램으로 그렸을 때 합집합 부분이다. outer join에는 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN이 있다.
-
LEFT OUTER JOIN: 왼쪽 테이블(A)에 있는 모든 데이터를 출력하고, 오른쪽 테이블(B)에서 연관된 데이터가 있으면 그것을 함께 출력하는 조인 방법이다. 만약 오른쪽 테이블에 연관된 데이터가 없다면, 오른쪽 테이블의 컬럼에는 NULL이 표시된다. 벤다이어그램으로 그렸을 때 왼쪽 테이블(A)의 모든 부분과 A와 B의 교집합 부분이 포함된다.
데이터베이스 비교
좋아, 아래에 MySQL, SQLite, MongoDB, Redis 각각의 장단점과 핵심 특징을 평문으로 정리했어.
MySQL
-
핵심 특징
관계형 데이터베이스(RDBMS)이다.
SQL 기반의 쿼리를 사용한다.
복잡한 JOIN과 트랜잭션을 지원한다.
대규모 시스템에서도 안정적으로 운용할 수 있다. -
장점
ACID 트랜잭션을 완벽하게 지원한다.
스키마 기반으로 데이터 무결성이 높다.
다양한 인덱싱, 제약 조건 설정이 가능하다.
커뮤니티가 활발하고 문서가 풍부하다. -
단점
스키마가 고정되어 있어 구조 변경이 번거롭다.
수평적 확장성이 낮다.
JSON과 같은 유연한 데이터 구조를 다루기 어렵다.
SQLite
-
핵심 특징
경량화된 임베디드 관계형 데이터베이스이다.
별도의 서버 없이 파일 단위로 동작한다.
간단한 애플리케이션이나 테스트에 적합하다. -
장점
설치가 필요 없고, 설정이 간단하다.
빠른 속도로 소규모 데이터를 처리할 수 있다.
로컬 환경이나 모바일 앱에 적합하다. -
단점
동시성 처리에 한계가 있다.
대규모 데이터 처리에는 부적합하다.
클라이언트-서버 모델이 아니라 네트워크를 통한 접근이 어렵다.
MongoDB
-
핵심 특징
NoSQL 기반의 문서지향 데이터베이스이다.
BSON 포맷(JSON과 유사)을 사용하여 유연한 구조를 지원한다.
스키마 없이 데이터를 저장할 수 있다. -
장점
유연한 스키마 구조로 빠른 개발이 가능하다.
수평적 확장이 쉽다.
복잡한 관계보다는 대량의 데이터를 빠르게 저장하고 검색할 수 있다. -
단점
데이터 무결성 보장이 약하다.
JOIN 기능이 제한적이다.
대규모 트랜잭션 처리에는 적합하지 않다.
Redis
-
핵심 특징
인메모리 기반의 키-값 저장소이다.
매우 빠른 데이터 읽기/쓰기 속도를 제공한다.
캐싱, 세션 저장, 순위 시스템 등에 자주 사용된다. -
장점
빠른 성능으로 실시간 데이터 처리에 적합하다.
다양한 데이터 구조(list, set, sorted set 등)를 지원한다.
pub/sub, TTL 등 고급 기능을 제공한다. -
단점
메모리에 모든 데이터를 저장하므로 메모리 용량에 제한이 있다.
데이터의 영속성은 설정에 따라 달라지며, 디스크 기반 DB보다 위험할 수 있다.
복잡한 쿼리나 다중 관계를 처리할 수 없다.
Index
인덱스는 데이터베이스에서 원하는 데이터를 더 빠르게 찾기 위해 사용하는 데이터 구조이며, 성능 최적화의 핵심 요소이다.
MySQL의 인덱스
- MySQL의 디폴트 인덱스 구조는 B+ Tree이다.
특히 InnoDB 스토리지 엔진에서 사용하는 기본 인덱스가 B+ Tree이다. - B+ Tree는 균형 잡힌 트리 구조로, 검색, 삽입, 삭제 연산이 빠르고 정렬된 데이터에 적합하다.
- 클러스터형 인덱스(Primary Key)와 보조 인덱스(Secondary Index) 모두 B+ Tree 구조를 기본으로 사용한다.
MySQL에서 B+ Tree 외 다른 인덱스 선택지
| 인덱스 타입 | 설명 |
|---|---|
| Hash | MEMORY 엔진에서 사용. 값의 해시를 기준으로 빠르게 조회하나, 범위 검색은 불가능하다. |
| R-Tree | 공간(지리) 데이터 인덱싱에 사용. 주로 SPATIAL INDEX로 활용된다. |
| Full-text | 텍스트 검색에 최적화된 인덱스. 자연어 기반 검색을 지원하며, MyISAM/InnoDB 모두에서 사용 가능하다. |
| BTREE | InnoDB에서 기본으로 쓰이는 B+ Tree와 같으며, 명시적으로 사용할 수도 있다. |
Redis의 인덱스 구조
- Redis는 전통적인 RDBMS가 아니며, 키-값 기반의 인메모리 데이터베이스이다.
- Redis 자체에는 RDBMS처럼 명시적인 “인덱스”가 존재하지 않지만, 데이터를 저장하는 구조에 따라 암묵적인 인덱싱 기능이 존재한다.
Redis에서의 자료구조 기반 인덱싱
| 자료구조 | 설명 |
|---|---|
| Dictionary(Hash Table) | Redis의 기본 자료구조. 키-값 조회는 O(1)로 매우 빠르며, 내부적으로 해시 테이블을 사용한다. |
| Sorted Set (ZSET) | 자동으로 정렬되는 구조. 점수(score) 기반으로 값을 정렬하며, 랭킹 시스템이나 범위 검색에 유용하다. |
| Set/List | 순서가 있거나 없는 컬렉션으로, 사용자 정의 인덱싱 로직을 통해 검색 구현이 가능하다. |
| Secondary Index | Redis는 기본적으로 지원하지 않지만, Sorted Set 등을 조합하여 사용자가 직접 구현할 수 있다. |
요약
- MySQL 기본 인덱스는 B+ Tree이며, MEMORY 엔진에서는 Hash, 공간 데이터를 위해 R-Tree 등도 선택 가능하다.
- Redis는 인덱스를 직접 정의하지 않지만, 내부적으로 해시 테이블 기반의 O(1) 조회 성능을 제공하며, Sorted Set 등의 구조로 사용자 정의 인덱싱이 가능하다.
락 전략 (비관적 vs 낙관적)
비관적 락
다른 트랜잭션이 데이터를 수정하는 것을 방지하기 위해 미리 락을 거는 방식이다. 데이터의 충돌 가능성이 높거나, 데이터 일관성을 강하게 보장해야 할 때 유용하다.
SELECT FOR UPDATE 구문
낙관적 락
충돌을 미리 예상하지 않고, 데이터 변경 시점에서만 충돌을 감지하여 처리하는 방식이다. 성능이 중요한 경우나, 충돌이 적은 시스템에 유리하다. 버전 필드 추가하여 구현된다.
MySQL InnoDB
클러스터링과 리플리케이션
알고리즘
sorting algorithm
https://gobyeonghu.github.io/algorithm/2024/11/06/sorting.html
허프만 코딩
허프만 코딩(Huffman Coding)은 1952년 데이비드 허프만(David Huffman)이 제안한 무손실 압축 알고리즘으로, 데이터의 각 문자를 가변 길이 코드로 인코딩하여 압축 효율을 극대화하는 방법이다. 이 방식은 데이터의 빈도에 따라 짧은 코드와 긴 코드를 부여하여 데이터를 압축한다. 특히 허프만 코딩은 데이터의 빈도가 높을수록 더 짧은 코드를 할당해, 데이터를 효율적으로 표현할 수 있다.
허프만 코딩의 주요 개념
허프만 코딩의 핵심 개념은 빈도 기반 가변 길이 인코딩이다. 자주 등장하는 문자에는 짧은 코드, 드물게 등장하는 문자에는 긴 코드를 부여하여 전체 데이터 크기를 줄인다. 이를 위해 이진 트리 구조를 활용하며, 이를 허프만 트리(Huffman Tree)라고 한다.
- 빈도 분석: 입력 데이터 내 각 문자의 출현 빈도를 계산해 가장 빈도가 높은 문자는 짧은 길이의 코드로, 빈도가 낮은 문자는 긴 길이의 코드로 매핑한다.
- 트리 구조: 허프만 코딩은 완전한 이진 트리 구조를 사용하며, 각 문자는 트리의 리프 노드로 저장된다.
- 접두사 코드(Prefix Code): 허프만 코딩은 접두사 코드를 사용한다. 즉, 어떤 문자 코드도 다른 문자의 코드의 접두사가 되지 않아, 데이터 디코딩 시 모호함이 없다. 이로써 디코딩이 고유하게 가능하다.
허프만 코딩의 알고리즘 단계
- 빈도 계산: 인코딩할 데이터에서 각 문자와 그 빈도를 구한다.
- 초기 노드 생성: 각 문자를 빈도와 함께 노드로 만든다. 각 노드는 트리의 리프 노드로서, 초기에는 독립적인 개별 노드로 존재한다.
- 트리 생성: 빈도가 가장 낮은 두 개의 노드를 선택해 새로운 노드로 병합한다. 이 과정은 단일 루트 노드가 될 때까지 반복된다.
- 새로운 노드는 선택한 두 노드의 빈도의 합을 빈도로 가지며, 왼쪽과 오른쪽 자식 노드로 연결된다.
- 이를 반복하면 루트에서 리프까지의 경로로 각 문자의 코드를 정의할 수 있는 트리가 완성된다.
- 코드 할당: 루트에서 리프까지의 경로를 따라 각 문자에 고유한 이진 코드(0과 1의 연속)를 할당한다. 일반적으로 왼쪽 경로에는
0, 오른쪽 경로에는1을 부여한다.
허프만 트리의 예시
문자열 “ABRACADABRA”에 대해 허프만 코딩을 수행해 보자. 우선 각 문자의 빈도를 계산하면 다음과 같다.
- 빈도 계산: A - 5회, B - 2회, R - 2회, C - 1회, D - 1회
이 빈도를 바탕으로 트리를 구축하는 단계는 다음과 같다.
- 각 문자를 빈도로 초기화한 독립적인 노드로 구성한다.
- 빈도가 가장 낮은 두 노드
C와D를 병합하여 새로운 노드를 생성하고 빈도를 2로 설정한다. - 두 번째로 빈도가 낮은
B와 새로운 노드(CD)를 병합하여 빈도가 4인 노드를 생성한다. - 나머지 노드들에 대해 이 과정을 반복하여 단일 루트 노드가 될 때까지 트리를 구성한다.
- 최종 트리에서 각 문자에 대해 루트에서 리프까지의 경로를 따라 코드를 할당한다.
이 트리를 통해 각 문자에 고유한 이진 코드를 할당하며, 예를 들어 A는 0, B는 101, C는 1000, D는 1001, R은 11 등으로 표현될 수 있다.
허프만 코딩의 장점과 단점
- 장점:
- 압축 효율성: 자주 등장하는 문자에 짧은 코드를 할당하므로 데이터 압축률이 높아진다.
- 무손실 압축: 원본 데이터와 동일하게 복원할 수 있어, 데이터 손실이 발생하지 않는다.
- 접두사 코드를 사용하므로 디코딩 과정에서 모호성이 발생하지 않는다.
- 단점:
- 고정된 빈도 기반: 데이터에 따라 빈도가 달라지므로, 데이터가 크게 변화할 경우 허프만 트리를 재구성해야 한다.
- 효율성 저하 가능성: 짧은 데이터에는 부가 데이터가 많아져 압축률이 낮아질 수 있다. 예를 들어 모든 문자가 거의 동일한 빈도를 갖는 데이터에서는 이점이 적다.
허프만 코딩의 활용 분야
허프만 코딩은 다양한 데이터 압축 및 무손실 전송 프로토콜에 널리 사용된다.
- 파일 압축: ZIP 파일이나 JPEG 이미지 형식에서 허프만 코딩을 사용해 압축률을 높인다.
- 데이터 전송: 빈도가 높은 데이터에 짧은 코드를 할당해 통신 트래픽을 줄인다.
- 정보 이론 및 통계적 코딩: 정보 엔트로피를 기반으로 가변 길이 코딩을 구현해 효율적인 데이터 저장을 지원한다.
허프만 코딩과 기타 압축 기법의 비교
허프만 코딩은 가변 길이의 무손실 압축 기법으로, 런-길이 인코딩(RLE)이나 Lempel-Ziv-Welch(LZW)와 같은 기법과 비교할 때 빈도 기반으로 압축률을 극대화한다는 점에서 차별화된다. 허프만 코딩은 접두사 코드를 사용해 각 코드가 유일하다는 점이 강점이며, 특정 데이터 분포에 대해 최적화된 압축을 제공한다. 그러나 특정 상황에서는 정적 코딩 방식의 효율성 저하가 있을 수 있다.
허프만 코딩은 컴퓨터 과학에서 매우 중요한 무손실 압축 기법으로, 데이터 빈도 기반으로 효율적인 압축을 가능하게 한다. 데이터 분포에 따라 최적의 압축률을 제공하며, 다양한 파일 포맷과 통신 시스템에서 그 유용성을 인정받고 있다.
손코딩
피보나치 수열의 N번째 값을 구하는 메소드
private static int recursiveFibonacci(int index) {
if (index <= 2){
return 1;
}
return recursiveFibonacci(index - 1) + recursiveFibonacci(index - 2);
}
private static int loopFibonacci(int index) {
int answer = 1;
int before = 1;
int temp;
for (int i = 2; i < index; i++) {
temp = answer;
answer += before;
before = temp;
}
return answer;
}
팩토리얼 N번째 값을 구하는 매소드
private static int recursiveFactorial(int num) {
if(num > 1) {
return recursiveFactorial(num -1) * num;
}
return 1;
}
private static int loopFactorial(int num) {
int answer = 1;
for(int i = 2; i <= num; i++) {
answer *= i;
}
return answer;
}
네트워크
HTTP 프로토콜
정의
HTTP(Hyper Text Transfer Protocol)이란 데이터를 주고 받기 위한 프로토콜이며, 서버/클라이언트 모델을 따른다.
특징
- Stateless
- Connectionless
- 장점
- 통신간의 연결 상태 처리나 상태 정보를 관리할 필요가 없어 서버 디자인이 간단
- 단점
- 이전 통신의 정보를 모르기 때문에 매번 인증을 해줘야 한다.
SSL(Secure Socket Layer)/TLS(ransport Layer Security)
인터넷을 통해 전달되는 정보를 보호하기 위해 개발한 통신 규약이다. TTP는 원래 TCP와 직접 통신했지만, HTTPS에서 HTTP는 SSL과 통신하고 SSL이 TCP와 통신함으로써 암호화와 증명서, 안전성 보호를 이용할 수 있다.
특징
- SSL(Secure Sockets Layer)은 암호화 기반 인터넷 보안 프로토콜
- 웹에서 전송되는 데이터를 암호화
- 데이터 무결성을 제공하기 위해 데이터에 디지털 서명하여 데이터가 의도된 수신자에 도착하기 전에 조작되지 않았다는 것을 확인
- SSL은 TLS(Transport Layer Security)이라는 또 다른 프로토콜의 바로 이전 버전
- SSL/TLS를 사용하는 웹사이트의 URL에는 “HTTP” 대신 “HTTPS”가 있다.
동작 방식
HTTPS(Hypertext Transfer Protocol Secure)는 SSL/TLS(보안 소켓 계층 및 전송 계층 보안)를 통해 HTTP 통신을 암호화하여 안전한 데이터 전송을 보장한다. 이 과정은 여러 단계로 구성되며, CA(인증 기관)를 통해 서버가 인증서를 발급받는 과정, SSL/TLS 핸드셰이크, 그리고 데이터 전송 과정까지 포함된다.
1. 서버 인증서 발급 과정 및 CA의 역할
-
서버 인증서 요청: 서버는 HTTPS 통신을 하기 위해 인증 기관(CA, Certificate Authority)으로부터 인증서를 발급받아야 한다. 이를 위해, 서버 관리자는 CSR(Certificate Signing Request)이라는 요청서를 생성한다. 이 요청서에는 서버의 공개 키, 서버의 도메인 이름, 조직 정보 등이 포함된다.
-
CSR 제출 및 CA 인증: 서버 관리자는 CSR을 CA에 제출한다. CA는 제출된 정보를 검토하여 서버의 신뢰성을 검증한다. 이 검증은 서버가 실제로 해당 도메인을 소유하고 있으며, 신뢰할 수 있는 조직인지 확인하는 과정을 포함한다.
-
인증서 발급: CA는 검증을 완료하면 인증서에 서버의 공개 키와 서버 정보를 포함하여 서명한다. 이 인증서는 신뢰된 CA의 공개 키를 사용해 확인할 수 있도록 되어 있으며, 이렇게 서명된 인증서를 서버에 발급한다. 이 과정에서 CA는 서버와의 통신에서 사용되는 신뢰 기반을 제공한다.
-
서버 인증서 설치: 서버는 발급된 인증서를 설치하고 HTTPS 통신에 사용한다. 이 인증서는 이후 클라이언트와 통신할 때 서버의 신뢰성을 증명하는 데 사용된다.
2. HTTPS 통신 과정 - SSL/TLS 핸드셰이크
SSL/TLS 핸드셰이크는 HTTPS 통신이 이루어질 때 클라이언트와 서버가 보안 연결을 설정하는 단계이다. 이 핸드셰이크 과정은 보통 다음과 같은 단계를 포함한다.
2-1. 클라이언트 Hello
클라이언트는 서버에 연결을 요청하며 첫 메시지로 Client Hello를 보낸다. 이 메시지에는:
- 클라이언트가 지원하는 암호화 방식 목록(예: AES, RSA, SHA 등)
- 사용할 수 있는 TLS 버전
- 무작위 난수(
Client Random) 등이 포함된다.
2-2. 서버 Hello
서버는 클라이언트의 Client Hello를 수신하고 응답한다. 이 응답 메시지인 Server Hello에는:
- 서버가 선택한 암호화 방식
- 무작위 난수(
Server Random) - 서버의 디지털 인증서 등이 포함된다.
서버는 클라이언트가 보낸 암호화 방식 중에서 선택하여 통신 방식을 결정한다.
2-3. 서버 인증서 검증 및 공개 키 교환
-
클라이언트는 서버의 디지털 인증서를 검증한다. 이 과정에서 클라이언트는 인증서를 발급한 CA의 공개 키를 사용해 서버 인증서를 확인한다. 인증서가 유효하면 서버가 신뢰할 수 있다고 판단한다.
-
서버 인증서가 유효하다고 판단되면, 클라이언트는 세션 키를 안전하게 교환하기 위해 서버의 공개 키를 사용해 대칭 키를 암호화한 후 서버에 전송한다.
2-4. 세션 키 생성 및 공유
-
클라이언트와 서버는 각각
Client Random과Server Random을 조합하여 세션 키를 생성한다. 이 세션 키는 이후의 통신을 암호화하는 데 사용된다. - 클라이언트와 서버는 서로 동일한 세션 키를 공유하게 되며, 이 키는 이후 데이터 전송의 암호화와 복호화에 사용된다. 세션 키는 대칭키 방식으로 사용된다.
-
세션 키를 안전하게 교환할 때는 비대칭키 알고리즘이 사용된다. SSL/TLS 핸드셰이크 과정에서 클라이언트는 서버의 공개 키를 이용해 생성된 세션 키를 암호화하고 이를 서버로 전송한다. 서버는 자신의 비공개 키를 사용해 암호화된 세션 키를 복호화하여 대칭키(세션 키)를 얻는다.
- 이 과정에서 비대칭키 알고리즘은 주로 RSA, ECDHE 등의 방법이 사용되며, 이 비대칭 암호화를 통해 클라이언트와 서버 간 세션 키가 안전하게 공유된다. 이후 데이터 전송은 대칭키 암호화 방식으로 진행되며, 이는 전송 속도와 성능을 높이는 데 도움을 준다.
2-5. 암호화 완료 통보 (Finished Message)
-
클라이언트와 서버는 각각 마지막 메시지로
Finished Message를 보낸다. 이 메시지는 세션 키로 암호화되어 전송되며, 암호화가 완료되었음을 알리는 신호이다. -
클라이언트와 서버가 모두
Finished Message를 수신하고 암호화가 성공하면, SSL/TLS 핸드셰이크가 완료되고 안전한 통신이 시작된다.
3. 데이터 암호화 통신
핸드셰이크가 완료된 후 클라이언트와 서버는 설정된 세션 키를 통해 데이터를 암호화하여 안전하게 통신한다. 이 과정에서의 세부 사항은 다음과 같다.
-
대칭키 암호화: HTTPS 통신이 시작되면, 클라이언트와 서버는 핸드셰이크 과정에서 생성된 세션 키를 사용하여 대칭 키 방식으로 데이터를 암호화하고 복호화한다. 대칭키 방식은 속도가 빠르고 효율적이기 때문에 보안성을 유지하면서 성능을 높일 수 있다.
-
데이터 무결성 확인: 클라이언트와 서버는 데이터 전송 중 무결성을 확인하기 위해 MAC(Message Authentication Code)을 사용하여 전송된 메시지의 변경 여부를 검사한다. 데이터가 도중에 수정되었다면 MAC 값이 달라지므로 무결성 검증을 통해 통신의 안전성을 확인할 수 있다.
-
통신 종료: 통신이 완료되면 클라이언트와 서버는 핸드셰이크에서 생성된 세션 키와 기타 암호화 정보를 삭제하여 보안 유지에 도움을 준다.
이와 같은 과정으로 HTTPS는 클라이언트와 서버 간의 통신을 암호화하여 중간에서의 도청 및 데이터 변조를 방지하며, CA와 인증서를 통해 서버의 신뢰성을 보장한다.
SSH
SSH(Secure Shell)는 네트워크를 통해 원격 시스템에 안전하게 접근하고 제어하기 위한 암호화된 프로토콜이다. 일반적으로 리눅스와 같은 운영체제에서 원격 서버에 안전하게 접속하여 명령어를 실행하거나 파일을 전송하는 데 사용된다. SSH는 네트워크를 통해 주고받는 데이터를 암호화하여 중간에서 발생할 수 있는 도청이나 변조로부터 데이터를 보호한다.
SSH의 주요 특징
- 보안성: 비대칭키와 대칭키 알고리즘을 조합하여 안전한 연결을 제공하며, 세션 중간에 발생할 수 있는 공격을 방지한다.
- 인증: 사용자가 서버에 접속할 때 사용자를 식별하는 인증 기능이 있다. 패스워드 인증 외에도 공개키 인증이 널리 사용되며, 이를 통해 사용자와 서버 간 신뢰를 설정한다.
- 데이터 암호화: 데이터 전송 중에는 대칭키 암호화를 사용하여 높은 성능을 유지하면서도 데이터 보안을 보장한다.
SSH 연결 및 동작 방식
-
세션 생성: 클라이언트가 서버에 SSH 연결을 요청하면 세션이 생성된다.
-
서버 인증서 검증: 서버는 자신의 공개 키를 클라이언트에 제공하여 서버 신뢰성을 검증할 수 있도록 한다. 클라이언트는 서버의 공개 키를 신뢰할 수 있는 서버인지 확인하는 단계로, 보통 한 번 승인된 서버의 공개 키를 로컬에 저장하고 이후 접속 시 이를 비교한다.
- 키 교환 및 세션 키 생성:
- Diffie-Hellman 등의 키 교환 알고리즘을 사용해 안전하게 세션 키를 생성한다. 이를 통해 클라이언트와 서버가 동일한 대칭 키를 공유하게 된다.
- 이 과정에서 비대칭키 알고리즘을 사용하여 중간자 공격을 방지한다.
-
인증: SSH는 패스워드 인증, 공개키 인증 등의 방식으로 클라이언트를 인증한다. 공개키 인증은 개인 키와 공개 키 쌍을 사용하여 클라이언트와 서버 간 신뢰를 확립하는 방식이다.
- 데이터 암호화: 세션이 설정된 후부터는 공유된 대칭 키를 사용하여 데이터가 암호화된다. 이를 통해 클라이언트와 서버 간의 데이터가 외부에 노출되지 않도록 보호된다.
SSH의 주요 기능
- 원격 명령어 실행: SSH를 통해 원격 시스템에 명령을 실행할 수 있다.
- 포트 포워딩: SSH 터널을 통해 네트워크 트래픽을 암호화하여 특정 포트를 안전하게 사용할 수 있게 한다.
- SCP/SFTP: SSH 기반으로 파일을 전송할 수 있는 SCP(Secure Copy Protocol)와 SFTP(Secure File Transfer Protocol)를 제공하여 원격 서버와 안전하게 파일을 주고받을 수 있다.
SSH와 HTTPS의 차이점
- 목적: HTTPS는 주로 웹 통신에서 보안된 데이터 전송을 위해 사용되고, SSH는 원격 접속을 안전하게 수행하기 위해 사용된다.
- 포트: HTTPS는 기본적으로 포트 443을 사용하고, SSH는 포트 22를 사용한다.
- 세션 키 교환 방식: HTTPS는 SSL/TLS 기반의 핸드셰이크 과정에서 서버의 인증서를 이용해 세션 키를 교환하는 반면, SSH는 Diffie-Hellman과 같은 키 교환 알고리즘을 사용한다.
Cookie & Session
웹 애플리케이션에서 사용자 상태 정보를 관리하기 위해 주로 사용하는 방법에는 쿠키(Cookie)와 세션(Session)이 있다. HTTP는 무상태(stateless) 프로토콜로, 각 요청 간에 상태가 유지되지 않기 때문에, 웹 서버와 클라이언트 간의 지속적인 연결 상태를 유지하기 위해 쿠키와 세션을 사용한다.
Cookie
쿠키는 웹 서버가 클라이언트(주로 웹 브라우저)에 저장하는 작은 데이터 파일로, 사용자의 컴퓨터에 저장되어 다음 요청 시 웹 서버에 자동으로 전송된다. 이를 통해 웹 서버는 사용자의 이전 요청 상태를 알 수 있다.
쿠키의 특징
- 클라이언트 측 저장: 클라이언트(브라우저)에서 저장되며, 서버가 쿠키 데이터를 브라우저에 전달하면 브라우저가 이를 저장하고 필요 시 전송한다.
- 데이터 용량 제한: 쿠키 데이터는 일반적으로 4KB 이하로 제한되며, 너무 큰 데이터를 담기에는 적합하지 않다.
- 만료 시간: 쿠키에는 만료 시간이 있으며, 만료 시간이 지나면 자동으로 삭제된다. 이 만료 시간을 설정함으로써 지속 쿠키와 세션 쿠키로 구분할 수 있다.
- 세션 쿠키: 브라우저가 닫힐 때까지 유지되며, 주로 로그인 세션 등에 사용된다.
- 지속 쿠키: 지정된 만료 기간 동안 브라우저에 저장되어 기간 내에 계속 사용 가능하다.
쿠키의 용도
- 세션 관리: 로그인, 장바구니, 사용자 설정 등 웹 사이트 사용 중 상태를 유지하는 데 사용된다.
- 개인화: 사용자에게 맞춘 콘텐츠나 설정을 저장하여, 사용자가 재방문 시 동일한 환경을 제공한다.
- 트래킹: 사용자 행동 데이터를 수집하여 마케팅 목적으로 사용하기도 한다.
쿠키의 구조
쿠키는 key=value 형태로 구성되며, 여러 가지 옵션을 포함할 수 있다. 예를 들어, 다음과 같은 쿠키 데이터가 서버에서 설정될 수 있다:
Set-Cookie: sessionId=abc123; Expires=Wed, 09 Jun 2023 10:18:14 GMT; Path=/; Secure; HttpOnly
- sessionId=abc123: 쿠키의 이름과 값
- Expires: 쿠키의 만료 날짜와 시간
- Path: 해당 쿠키가 적용될 URL 경로
- Secure: HTTPS로만 쿠키 전송
- HttpOnly: JavaScript로 접근할 수 없도록 설정하여 보안 강화
Session
세션은 웹 서버에서 관리하는 상태 정보로, 사용자와 서버 간의 일시적인 연결 상태를 유지하기 위한 수단이다. 서버는 클라이언트와의 연결이 유지되는 동안 세션 ID를 통해 클라이언트를 식별하고 각 사용자별 데이터를 서버에 저장한다.
세션의 특징
- 서버 측 저장: 쿠키와 달리 세션 데이터는 서버에 저장되므로 클라이언트는 세션 ID만 갖고 있는다.
- 유한한 수명: 세션은 일반적으로 일정 시간 동안 유효하며, 사용자가 일정 시간 동안 활동이 없거나 브라우저를 닫으면 세션이 만료된다.
- 세션 ID: 서버는 클라이언트에게 세션 ID라는 고유 값을 부여하여 각 사용자를 식별하며, 이 세션 ID는 쿠키에 저장하여 클라이언트가 서버에 요청할 때마다 전송된다.
세션의 용도
- 로그인 상태 유지: 로그인한 사용자를 식별하고 상태를 유지하기 위해 주로 사용된다.
- 장바구니 기능: 전자상거래 사이트에서 장바구니 항목을 서버에 유지하여 사용자가 웹 사이트를 떠났다 돌아와도 데이터를 보존할 수 있게 한다.
- 사용자 활동 추적: 각 사용자의 행동을 추적하여 맞춤형 서비스를 제공하는 데 사용된다.
세션의 구조 및 동작 방식
- 클라이언트 요청: 클라이언트가 서버에 처음 접속하면, 서버는 새로운 세션을 생성하고 세션 ID를 클라이언트에게 전달한다.
- 세션 ID 저장: 세션 ID는 주로 쿠키에 저장되며, 이후 클라이언트의 모든 요청에 세션 ID가 포함된다.
- 세션 데이터 저장: 서버는 세션 ID를 통해 각 사용자의 세션 데이터를 관리하고, 데이터는 데이터베이스나 메모리와 같은 서버 측 저장소에 저장된다.
- 세션 유지 및 종료: 세션 만료 시간이나 사용자의 로그아웃 시 세션 데이터는 삭제된다.
Cookie와 Session의 차이점
| 구분 | 쿠키 (Cookie) | 세션 (Session) |
|---|---|---|
| 저장 위치 | 클라이언트(브라우저)에 저장 | 서버에 저장 |
| 용량 | 보통 4KB 이하로 제한 | 서버가 허용하는 범위 내에서 사용 가능 |
| 보안 | 상대적으로 보안에 취약 | 서버에 저장되어 상대적으로 안전 |
| 수명 | 만료 시간에 따라 달라짐 | 브라우저 종료 시 또는 설정된 만료 시간 후 종료 |
| 용도 | 사용자 추적, 상태 저장, 개인화 | 로그인 상태 유지, 사용자별 데이터 유지 |
쿠키와 세션의 상호작용
쿠키와 세션은 보통 함께 사용된다. 예를 들어, 세션 ID는 클라이언트의 쿠키에 저장되어 클라이언트가 서버에 재접속할 때마다 세션 ID를 보내 서버가 사용자 세션을 유지하도록 한다. 이를 통해 각 사용자 상태를 유지하며 지속적인 웹 서비스 사용이 가능하게 한다.
www.naver.com에 접속 과정
웹 브라우저에서 www.naver.com에 접속하는 과정은 여러 단계로 이루어져 있으며, 다음과 같은 세부 단계로 설명할 수 있다.
- URL 입력
- 사용자는 웹 브라우저의 주소창에
www.naver.com을 입력하고 Enter 키를 누른다.
- 사용자는 웹 브라우저의 주소창에
- DNS 조회
- 웹 브라우저는 입력된 URL에서 도메인 이름을 추출한다. 이 경우
www.naver.com이다. - 브라우저는 해당 도메인 이름에 대한 IP 주소를 찾기 위해 DNS(Domain Name System) 서버에 요청을 보낸다.
- DNS 서버는 요청을 받고, 해당 도메인에 대한 IP 주소를 조회하여 반환한다.
- 예를 들어, DNS 서버가
203.133.168.82라는 IP 주소를 반환할 수 있다.
- 예를 들어, DNS 서버가
- 웹 브라우저는 입력된 URL에서 도메인 이름을 추출한다. 이 경우
- TCP 연결
- 브라우저는 받은 IP 주소를 사용하여 웹 서버에 연결하기 위해 TCP(Transmission Control Protocol) 연결을 설정한다.
- TCP는 3-way handshake 과정을 통해 연결을 수립한다:
- SYN: 브라우저가 웹 서버에 연결 요청을 보낸다.
- SYN-ACK: 웹 서버가 요청을 수락하고, 확인 응답을 보낸다.
- ACK: 브라우저가 응답을 수신하고 연결이 완료된다.
- HTTPS 연결 (SSL/TLS 핸드셰이크)
- 웹 서버가 HTTPS를 사용하는 경우, SSL/TLS 핸드셰이크가 진행된다:
- 클라이언트 헬로: 브라우저가 웹 서버에 SSL/TLS 버전, 지원하는 암호화 알고리즘, 랜덤 데이터를 포함한 메시지를 보낸다.
- 서버 헬로: 웹 서버가 클라이언트의 요청을 수락하고 사용할 SSL/TLS 버전과 암호화 알고리즘을 선택하여 응답한다.
- 서버 인증서 전송: 웹 서버는 자신의 인증서를 클라이언트에게 전송한다. 클라이언트는 이 인증서를 검증하여 서버의 신뢰성을 확인한다.
- 프리마스터 시크릿 생성: 브라우저가 프리마스터 시크릿을 생성하고, 서버의 공개 키를 사용하여 암호화한 후 서버에 전송한다.
- 세션 키 생성: 서버와 브라우저는 동일한 세션 키를 생성하여 비밀 통신을 위한 준비가 완료된다.
- 웹 서버가 HTTPS를 사용하는 경우, SSL/TLS 핸드셰이크가 진행된다:
- HTTP 요청 전송
- TCP 연결이 완료되고 SSL/TLS 핸드셰이크가 끝난 후, 브라우저는 HTTP 요청을 웹 서버에 전송한다.
- 예를 들어, GET 요청을 통해
www.naver.com의 홈 페이지를 요청할 수 있다:GET / HTTP/1.1 Host: www.naver.com
- 서버의 요청 처리
- 웹 서버는 요청을 수신하고, 요청된 페이지를 생성하여 클라이언트에게 응답한다.
- 이 과정에서 서버는 데이터베이스에 쿼리를 실행하거나, 캐시된 데이터를 사용하여 요청을 처리할 수 있다.
- HTTP 응답 수신
- 웹 서버가 요청을 처리한 후, 클라이언트에게 HTTP 응답을 반환한다. 응답의 예시는 다음과 같다:
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8 Content-Length: 12345 [HTML 콘텐츠] - 응답 코드
200 OK는 요청이 성공적으로 처리되었음을 나타낸다.
- 웹 서버가 요청을 처리한 후, 클라이언트에게 HTTP 응답을 반환한다. 응답의 예시는 다음과 같다:
- HTML 렌더링
- 브라우저는 서버에서 받은 HTML 콘텐츠를 파싱하여 웹 페이지를 렌더링한다.
- 이 과정에서 추가로 필요한 CSS 파일, JavaScript 파일, 이미지 등의 리소스를 요청하기 위해 추가적인 HTTP 요청을 보낼 수 있다.
- 페이지 표시
- 모든 리소스가 로드되면 브라우저는 완전한 웹 페이지를 사용자에게 표시한다.
- 사용자는 이제
www.naver.com의 콘텐츠를 상호작용할 수 있게 된다.
- 상태 유지 (선택적)
- 사용자가 로그인하거나 특정 작업을 수행할 경우, 웹 애플리케이션은 쿠키 또는 세션을 통해 상태 정보를 유지할 수 있다.
- 이를 통해 사용자는 웹 사이트의 여러 페이지를 탐색하면서도 지속적인 사용자 경험을 유지할 수 있다.
이와 같이, 사용자가 웹 브라우저에서 www.naver.com에 접속하는 과정은 복잡하지만 잘 정의된 여러 단계로 이루어져 있다. 각 단계는 안정적이고 효율적인 웹 통신을 보장하기 위해 필요한 과정이다.
OSI 7 layer & TCP/IP Protocol
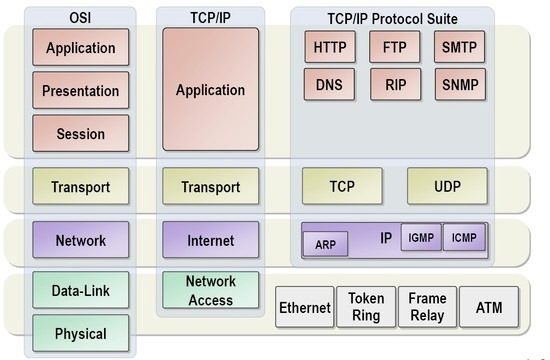
네트워크의 OSI 7 계층 모델과 TCP/IP 모델은 컴퓨터 네트워크의 주요한 두 가지 참조 모델로, 데이터 통신을 효율적이고 안정적으로 이루어지게 합니다. OSI 모델은 네트워크 통신을 7단계로 세분화하여 각 단계마다 역할을 정의하고, TCP/IP는 이를 실질적인 프로토콜로 구현하여 인터넷 통신의 표준이 되었습니다. 아래는 OSI 7 계층과 TCP/IP 프로토콜에 대한 상세 설명입니다.
1. OSI 7 Layer Model
OSI 모델(Open Systems Interconnection Model)은 ISO(국제 표준화 기구)에서 제정한 네트워크 통신 모델로, 계층별로 네트워크에서 수행해야 할 기능을 분리하여 정의하고 있습니다. 각 계층은 독립적이면서도 상호작용하여 전체 통신 프로세스를 담당합니다.
계층별 역할과 기능
- 물리 계층 (Physical Layer)
- 기능: 전기 신호 또는 광신호를 통해 데이터를 물리적으로 전송
- 기술: 케이블, 스위치, 허브, 리피터
- 설명: 데이터 전송을 위한 기계적, 전기적 인터페이스를 정의합니다. 전송 매체와 전기적 신호를 통해 0과 1의 비트 스트림을 전송하며, 비트 전송의 규격(전압, 케이블 종류)을 정의합니다.
- 문제: 비트 에러, 전송 매체 간 간섭 등
- 프로토콜 예시: USB, Ethernet
- 데이터 링크 계층 (Data Link Layer)
- 기능: 물리 계층에서 신뢰성 있는 전송을 지원
- 기술: MAC 주소를 통한 네트워크 장치 식별, 오류 검출 및 흐름 제어
- 설명: 프레임 단위로 데이터를 전송하고, 프레임의 오류 검출 및 수정(오류 복구)은 수행하지 않으며 오류 검출에 집중합니다. 이 계층에서는 MAC 주소를 이용하여 장치를 식별합니다.
- 문제: 충돌, 혼잡 등
- 프로토콜 예시: Ethernet, PPP, Wi-Fi
- 네트워크 계층 (Network Layer)
- 기능: 데이터가 네트워크를 통해 목적지까지 도달하는 경로를 결정
- 기술: IP 주소를 통해 장치를 식별하고, 최적의 경로 선택을 수행
- 설명: 라우팅 프로토콜을 통해 패킷을 최적의 경로로 전달하며, 네트워크 간 데이터 전달을 수행합니다. IP 주소는 장치의 위치를 나타냅니다.
- 문제: 경로 지연, 경로 손실
- 프로토콜 예시: IP, ICMP, ARP
- 전송 계층 (Transport Layer)
- 기능: 데이터의 신뢰성 있는 전송을 보장
- 기술: 포트 번호 사용, 오류 검출 및 복구
- 설명: 세그먼트 단위로 데이터 전송을 관리하며, TCP(연결 지향)와 UDP(비연결 지향)로 세션을 설정하고 유지합니다. 오류 검출 및 복구 기능도 수행합니다.
- 문제: 데이터 유실, 순서 어긋남
- 프로토콜 예시: TCP, UDP
- 세션 계층 (Session Layer)
- 기능: 세션 관리(연결 설정, 유지, 종료)
- 기술: 세션 재동기화, 연결 복구
- 설명: 애플리케이션 간 연결을 설정하고 유지하며, 오류 발생 시 세션을 복구합니다.
- 프로토콜 예시: NetBIOS, PPTP
- 표현 계층 (Presentation Layer)
- 기능: 데이터 형식 변환(암호화, 압축, 인코딩)
- 기술: 데이터 압축, 암호화, 변환
- 설명: 데이터 형식의 차이를 해결하며, 데이터 암호화와 복호화를 통해 보안성을 높입니다.
- 프로토콜 예시: SSL, TLS
- 응용 계층 (Application Layer)
- 기능: 사용자와 네트워크 간 상호작용 제공
- 기술: 네트워크 애플리케이션 인터페이스 제공
- 설명: 사용자가 네트워크를 통해 데이터를 송수신할 수 있도록 기능을 제공합니다.
- 프로토콜 예시: HTTP, FTP, SMTP, DNS
2. TCP/IP Protocol Model
TCP/IP 모델은 OSI 모델을 바탕으로 실질적인 프로토콜을 구현한 모델로, 인터넷 통신의 표준이자 네트워크의 근간을 이루는 모델입니다. OSI 모델보다 간결하게 구성되어 4계층으로 이루어져 있습니다.
TCP/IP 계층별 역할과 기능
- 네트워크 인터페이스 계층 (Network Interface Layer)
- 기능: 데이터 링크 및 물리 계층과 같은 역할 수행
- 설명: 데이터를 네트워크로 전송하기 위한 인터페이스를 제공합니다. 이 계층은 OSI의 물리 계층과 데이터 링크 계층의 기능을 포함합니다.
- 프로토콜 예시: Ethernet, Wi-Fi
- 인터넷 계층 (Internet Layer)
- 기능: IP 주소 할당, 경로 결정
- 설명: 데이터를 패킷으로 나누고 목적지까지 라우팅하는 역할을 수행하며, OSI 모델의 네트워크 계층에 해당합니다.
- 프로토콜 예시: IP, ICMP, ARP
- 전송 계층 (Transport Layer)
- 기능: 데이터의 신뢰성 있는 전송 보장
- 설명: 데이터가 올바른 순서로 전달되도록 관리하며, TCP와 UDP 프로토콜을 통해 데이터 송수신을 제어합니다.
- 프로토콜 예시: TCP, UDP
- 응용 계층 (Application Layer)
- 기능: 네트워크 서비스 제공
- 설명: 사용자가 네트워크 서비스를 사용할 수 있도록 지원하며, OSI 모델의 세션, 표현, 응용 계층의 기능을 모두 수행합니다.
- 프로토콜 예시: HTTP, FTP, DNS, SMTP
OSI 모델과 TCP/IP 모델의 비교
| OSI 계층 | TCP/IP 계층 | 기능 요약 |
|---|---|---|
| 물리 계층 | 네트워크 인터페이스 계층 | 전기적, 기계적 데이터 전송 |
| 데이터 링크 계층 | 네트워크 인터페이스 계층 | 프레임 생성, MAC 주소를 통한 통신 |
| 네트워크 계층 | 인터넷 계층 | IP 주소를 통해 경로 선택 및 데이터 전송 |
| 전송 계층 | 전송 계층 | 데이터의 신뢰성 보장, 포트 번호 사용 |
| 세션 계층 | 응용 계층 | 세션 설정 및 유지 관리 |
| 표현 계층 | 응용 계층 | 데이터 암호화 및 형식 변환 |
| 응용 계층 | 응용 계층 | 사용자 서비스 제공 (웹, 메일, 파일 전송 등) |
주요 프로토콜 설명
- TCP (Transmission Control Protocol)
- 연결형 프로토콜로 3-Way Handshake와 4-Way Handshake를 통해 신뢰성 있는 데이터 전송을 보장합니다. 패킷의 순서 제어 및 재전송 기능을 제공합니다.
- UDP (User Datagram Protocol)
- 비연결형 프로토콜로, 빠른 전송이 필요하지만 신뢰성이 낮아도 되는 경우에 사용됩니다. 스트리밍, 온라인 게임 등에 주로 사용됩니다.
- IP (Internet Protocol)
- 네트워크 계층에서 사용되며, 패킷을 목적지까지 라우팅하는 역할을 수행합니다. IP 주소 체계로 장치를 식별하고, 데이터가 최적의 경로로 이동할 수 있게 합니다.
- HTTP/HTTPS
- 웹 브라우저와 웹 서버 간 데이터를 전송하는 데 사용됩니다. HTTPS는 암호화된 통신을 지원하여 보안성을 높입니다.
- DNS (Domain Name System)
- 도메인 이름을 IP 주소로 변환하여 사용자가 쉽게 네트워크 자원을 접근할 수 있도록 도와줍니다.
요약
OSI 7 계층 모델과 TCP/IP 프로토콜 모델은 네트워크 통신의 이론적 및 실질적 구조를 제공하며, 각 계층은 네트워크 통신의 특정 부분을 담당하여 통신의 효율성을 극대화합니다. OSI 모델은 계층별 역할을 명확히 정의하여 교육과 이론에 적합하며, TCP/IP 모델은 실질적인 인터넷 통신에 표준화된 프로토콜을 제공합니다. 각 계층의 역할과 프로토콜을 이해함으로써 네트워크의 기본 구조와 동작 방식을 파악할 수 있습니다.
3-Way Handshake와 4-Way Handshake
- 3-Way Handshake: TCP의 접속 과정
- 4-Way Handshake: TCP의 접속 해제 과정
포트(PORT) 상태 정보
- CLOSED: 포트가 닫힌 상태
- LISTEN: 포트가 열린 상태로 연결 요청 대기 중
- SYN_RCV: SYN 요청을 받고 응답 대기 중
- ESTABLISHED: 포트 연결 상태
플래그 정보
- TCP Header에는 CONTROL BIT(플래그 비트, 6bit)가 있으며, “URG-ACK-PSH-RST-SYN-FIN” 의미를 가진다. 각 비트가 1이면 해당 패킷 내용 나타냄.
- SYN (000010): 연결 설정 및 세션 연결에 사용, 시퀀스 번호 전송
- ACK (010000): 응답 확인, 받은 패킷 확인, 모든 세그먼트의 ACK 비트는 1로 지정
- FIN (000001): 연결 해제 시 사용, 더 이상 전송할 데이터가 없음을 의미
TCP의 3-Way Handshake
- 개념: TCP 통신으로 데이터를 전송하기 위해 네트워크 연결을 설정하는 과정.
- 기본 메커니즘: 양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장.
- PAR (Positive Acknowledgement with Re-transmission)을 통해 신뢰적 통신 제공.
- 데이터 유닛을 재전송하여 양방향 통신에서 3개의 Segment 교환.
작동 방식
- Step 1 (SYN)
클라이언트가 서버와 연결하려고 SYN 전송 (seq: x).- 포트 상태: Client - CLOSED → SYN_SENT, Server - LISTEN
- Step 2 (SYN + ACK)
서버가 SYN(x) 수신 후, ACK와 SYN 패킷 전송 (seq: y, ACK: x+1).- 포트 상태: Client - CLOSED, Server - SYN_RCV
- Step 3 (ACK)
클라이언트가 ACK(x+1)과 SYN(y) 수신 후, ACK(y+1) 서버로 전송.- 포트 상태: Client - ESTABLISHED, Server - SYN_RCV → ESTABLISHED
TCP의 4-Way Handshake
- 개념: 연결 해제(Connecntion Termination) 과정으로, FIN 플래그 사용.
- FIN (finish): 세션 종료 및 더 이상 보낼 데이터가 없음을 나타냄.
작동 방식
-
STEP1 (Client → Server : FIN + ACK)
클라이언트가 close() 호출 후, 연결 종료 FIN 패킷 전송. -
STEP2 (Server → Client : ACK)
서버는 FIN 수신 후 ACK 전송, CLOSE_WAIT 상태. 클라이언트는 FIN_WAIT_2로 전환. -
STEP3 (Server → Client : FIN)
서버가 모든 데이터 전송 후 FIN 전송, LAST_ACK 상태로 전환. -
STEP4 (Client → Server : ACK)
클라이언트는 FIN 수신 후, ACK 전송. TIME_WAIT 후 종료 (CLOSED).
주의사항
-
3-Way Handshake와 4-Way Handshake 단계 차이
클라이언트가 데이터 전송을 완료해도 서버에는 추가 데이터가 남아있을 수 있습니다. 이 때문에 서버는 FIN에 대한 ACK를 먼저 전송하고, 모든 데이터를 전송한 후에 FIN 메시지를 전송하여 연결을 종료합니다. -
FIN 패킷보다 늦게 도착하는 패킷의 처리
서버가 FIN 패킷을 보내기 전에 다른 패킷이 지연되거나 재전송으로 인해 FIN보다 늦게 도착할 경우, 클라이언트는 서버로부터 FIN을 수신해도 일정 시간(TIME_WAIT, 기본 240초) 동안 세션을 남겨 두고 잉여 패킷을 기다립니다. -
ISN(Initial Sequence Number)을 난수로 설정하는 이유
포트 번호는 유한 범위 내에서 재사용되며, 순차적인 번호를 사용할 경우 이전의 연결로부터 오는 패킷으로 오인될 수 있습니다. 이를 방지하기 위해 난수를 이용해 ISN을 설정하여 보안성과 패킷 구분을 강화합니다.
TCP와 UDP
트랜스포트 계층에서 패킷을 “세그먼트”라 하고, UDP에서는 이를 “데이터그램”이라고도 한다.
TCP (Transmission Control Protocol)
- 기능: IP가 배달을 담당하고, TCP는 패킷 추적 및 관리를 담당한다.
- 연결 설정/해제: 3-way handshaking으로 연결을 설정하고, 4-way handshaking으로 해제한다.
- 제어 기능: 흐름 제어와 혼잡 제어 기능을 통해 높은 신뢰성을 보장한다.
- 속도: UDP보다 속도가 느리다.
- 특징: 전이중(Full-Duplex) 통신과 점대점(Point to Point) 방식을 지원한다.
UDP (User Datagram Protocol)
- 데이터 단위: 데이터를 독립적 관계를 가진 데이터그램 단위로 처리한다.
- 비연결형 프로토콜: 연결 설정 및 해제 과정이 없으며, 패킷 순서 부여 및 재조립, 흐름 제어, 혼잡 제어 기능이 없다.
- 속도: TCP보다 속도가 빠르고, 네트워크 부하가 적다.
- 신뢰성: 데이터 전송 신뢰성은 낮지만, 연속성이 중요한 실시간 서비스(예: 스트리밍)에 적합하다.
- 특징: 비연결형 서비스로 데이터그램 방식을 제공하며, 데이터 송수신 시 신호 절차를 거치지 않는다.
- 오류 검출: UDP 헤더의 CheckSum 필드를 통해 최소한의 오류 검출만 수행한다.
TCP와 UDP 비교
- 포트 관리: UDP와 TCP는 각기 다른 포트 주소 공간을 관리하므로, 두 프로토콜에서 동일한 포트 번호를 사용할 수 있다.
- 동적 포트 할당: 동일 모듈(UDP 또는 TCP) 내에서 다중 커넥션을 설정할 때 동적으로 다른 포트 번호를 할당한다. (동적 할당 포트 범위: 49,152~65,535)
IP
Connection Timeout & Read Timeout
인증 인가
세션 기반 인증
- 정의: 클라이언트의 상태 정보를 서버에 저장하여 사용자 인증을 수행하는 방식이다.
- 특징:
- Stateful 구조: 서버에 클라이언트의 세션 정보를 저장하므로 상태를 유지한다.
- 서버 자원 소모: 세션 정보를 저장하기 위해 서버의 메모리를 사용한다.
- 세션 유효성: 서버가 재시작될 경우 세션 정보가 사라지며, 로드 밸런싱에 복잡성을 추가할 수 있다.
토큰 기반 인증
- 정의: 상태 정보를 서버에 저장하지 않고, 클라이언트에게 발급된 토큰을 이용하여 인증을 수행하는 방식이다.
- 특징:
- Stateless 구조: 클라이언트가 가진 토큰을 통해 인증 정보를 확인하며, 서버는 상태를 저장하지 않는다.
- 확장성: 여러 플랫폼과 기기에서 동일한 토큰을 사용하여 인증할 수 있다.
- 장애 복구: 서버가 재시작되더라도 클라이언트가 토큰을 보유하고 있으면 인증이 가능하다.
인증 방식의 적합성
- 세션 기반 인증 사용 사례:
- 전통적인 웹 애플리케이션에서 로그인 후 사용자 경험을 개선할 필요가 있을 때 적합하다.
- 토큰 기반 인증 사용 사례:
- RESTful API나 모바일 애플리케이션과 같은 Stateless 환경에서 적합하다. 이는 서버와 클라이언트 간의 독립성을 높이고, 다양한 플랫폼 간의 인증 처리를 용이하게 한다.
JWT (JSON Web Token)
- 정의: Claim 기반의 웹 토큰으로, 정보를 안전하게 전달하기 위해 Self-Contained 방식으로 설계되었다.
- 구성 요소:
- 헤더(Header): 토큰의 타입과 해시 암호화 알고리즘을 포함한다.
- 내용(Payload): 사용자가 담고자 하는 정보를 포함하며, JSON(Key/Value) 형태로 구성된다.
- 서명(Signature): 토큰의 유효성을 검증하기 위해 헤더와 내용을 인코딩하여 생성한 고유한 암호화 코드이다.
결론
세션 기반 인증과 토큰 기반 인증은 각각의 상황에 맞는 장단점이 있으며, JWT는 이러한 인증 방식에서 유용하게 활용될 수 있다. 각 기술의 특성을 이해하고, 적절한 상황에 맞게 사용하는 것이 중요하다.
NAT(Network Address Translation)
NAT는 사설 IP 주소를 공인 IP 주소로 변환하는 기술 인터넷은 공인 IP 주소만을 인식하기 때문에, 사설망에 있는 컴퓨터가 외부 인터넷과 통신하려면 NAT이 필요하다.
종류
-
Static NAT는 고정된 사설 IP 주소와 공인 IP 주소를 1:1로 매핑한다.
-
Dynamic NAT는 사설 IP 주소를 공인 IP 풀에서 임의로 할당받아 매핑한다.
-
PAT(Port Address Translation)은 여러 사설 IP 주소가 하나의 공인 IP 주소를 포트 번호를 기준으로 공유하는 방식이며, 가장 일반적으로 사용된다.
사설 ip
사설 IP 주소는 내부 네트워크에서만 사용되는 IP 주소로, 인터넷에서는 직접 사용될 수 없다.
인터넷에 접속하려면 NAT를 통해 공인 IP로 변환되어야 한다.
사설 IP 주소는 RFC 1918에 정의되어 있으며, 다음과 같은 범위를 갖는다:
| 클래스 | 주소 범위 | 서브넷 마스크 | 비고 |
|---|---|---|---|
| A 클래스 | 10.0.0.0 ~ 10.255.255.255 | 255.0.0.0 | 대규모 네트워크에 적합 |
| B 클래스 | 172.16.0.0 ~ 172.31.255.255 | 255.240.0.0 | 중간 규모 네트워크 |
| C 클래스 | 192.168.0.0 ~ 192.168.255.255 | 255.255.0.0 | 소규모 네트워크에서 가장 흔히 사용됨 |
서브넷
서브넷(Subnet)은 하나의 IP 네트워크를 여러 개의 작은 네트워크(서브 네트워크)로 나누는 것을 말한다.
이 과정은 서브넷팅(Subnetting)이라고 하며, 큰 네트워크를 효율적으로 관리하고, IP 주소를 낭비 없이 사용하기 위해 사용된다.
IP 주소는 크게 두 부분으로 나뉜다:
네트워크 주소 부분과 호스트 주소 부분이다.
서브넷 마스크(Subnet Mask)는 이 둘을 구분하는 기준이 되는 값이다.
예를 들어,
- IP 주소:
192.168.1.10 - 서브넷 마스크:
255.255.255.0
이면, 앞의 192.168.1까지는 네트워크 주소이고, 마지막 10은 호스트 주소가 된다.
이 경우 한 네트워크 내에 최대 254개의 호스트(0과 255 제외)를 둘 수 있다.
서브넷의 주요 목적
-
네트워크 분리
하나의 물리적 네트워크를 여러 논리적 네트워크로 나눌 수 있다. -
트래픽 제어
브로드캐스트 범위를 줄여 네트워크 부하를 낮출 수 있다. -
보안 향상
네트워크를 분리해 접근을 제한하거나 방화벽 적용이 쉬워진다. -
IP 효율성
불필요하게 큰 네트워크를 작게 나누어 IP 자원을 절약할 수 있다.
CIDR 표기
서브넷은 종종 CIDR 표기법으로 나타낸다.
예를 들어 192.168.1.0/24는 서브넷 마스크 255.255.255.0을 의미한다.
여기서 /24는 앞 24비트가 네트워크 주소라는 뜻이다.
흐름:
-
전체 IP 대역을 먼저 할당받는다
예를 들어192.168.0.0/24→ 이건 256개의 IP를 쓸 수 있는 범위.
(보통 이건 회사나 조직이 내부 네트워크에서 설정하는 범위로 공인 IP는 ISP로부터 받지만, 사설 IP는 직접 설정 가능하다) - 그 안에서 서브넷을 나눈다 (서브넷팅)
예를 들어,192.168.0.0/26→ 64개 IP192.168.0.64/26→ 64개 IP192.168.0.128/26→ 64개 IP192.168.0.192/26→ 64개 IP
이런 식으로 나누면 같은
192.168.0.0/24안에서도 네트워크를 4개로 쪼갤 수 있다. - 각 부서나 용도에 따라 서브넷을 배정
예:- 개발팀:
192.168.0.0/26 - 마케팅팀:
192.168.0.64/26 - 회의실 장비:
192.168.0.128/26 - 서버용:
192.168.0.192/26
- 개발팀:
장점
- IP 낭비 없이 필요한 만큼만 나눌 수 있음
- 네트워크 구성이 더 유연하고 체계적임
- 트래픽 분산과 보안 설정이 용이함
HTTP 버전
HTTP는 버전이 올라가면서 성능 최적화와 병목 해결, 보안 등의 측면에서 지속적으로 발전해왔다. 각 버전별 특징을 간단하게 정리하면 다음과 같다:
HTTP/0.9 (1991)
- HTML 파일 하나만 전송 가능 (텍스트 기반)
- 요청 메서드: GET만 존재
- 헤더 없음, 상태 코드 없음
- 매우 단순한 구조
예:
GET /index.html
HTTP/1.0 (1996)
- 헤더 추가, 상태 코드 도입
- 다양한 MIME 타입 지원
- 지속 연결 없음 → 요청마다 TCP 연결 재사용 불가
문제: 이미지 등 리소스 여러 개 요청하면 매번 연결됨 → 느림
HTTP/1.1 (1997~)
- Persistent Connection (Keep-Alive): 연결 재사용 가능
- 파이프라이닝 도입 (하지만 대부분 비활성화됨)
- Host 헤더 필수화 → 가상호스팅 가능
- Chunked Transfer-Encoding 도입 → 스트리밍 가능
한 연결에 여러 요청을 보내도 응답 순서를 기다려야 해서 병목 발생 (Head-of-Line Blocking)
HTTP/2 (2015)
- 바이너리 프로토콜로 전환 (기존은 텍스트 기반)
- 멀티플렉싱: 하나의 연결에서 여러 요청/응답 동시 처리 가능 → HOLB 해결
- 헤더 압축 (HPACK): 중복 줄이고 성능 향상
- 서버 푸시: 클라이언트 요청 전에 필요한 리소스 미리 전송 가능
성능이 대폭 향상됨, 브라우저 대부분 지원
HTTP/3 (2022 정식)
- TCP 대신 QUIC(UDP 기반) 사용
- 연결 지연 최소화: 핸드셰이크 감소 (TLS 1.3 내장)
- HOLB 문제 완전 해결 (TCP는 한 패킷 문제 시 전체 막힘)
- 빠른 재전송, 스트림 단위 에러 격리 가능
브라우저, CDN 등에서 점차 채택 중 (Chrome, Cloudflare 등)
버전별 요약 표
| 버전 | 주요 특징 |
|---|---|
| HTTP/0.9 | GET만 지원, 헤더 없음 |
| HTTP/1.0 | 헤더, 상태코드, MIME 타입 도입, 비지속 연결 |
| HTTP/1.1 | Keep-Alive, 파이프라이닝, Host 헤더, 성능 개선 |
| HTTP/2 | 바이너리, 멀티플렉싱, 헤더 압축, 서버 푸시 |
| HTTP/3 | QUIC 기반, 지연 최소화, HOLB 완전 제거, TLS 내장 |
운영체제
프로세스와 스레드
페이지 교체 알고리즘
페이징 기법으로 메모리를 관리하는 운영체제에서 필요한 페이지가 주기억장치에 적재되지 않았을 시(페이징 부재시) 어떤 페이지 프레임을 선택해 교체할 것인지 결정하는 방법
- FIFO(first in first out)
- 메모리에 올라온 지 가장 오래된 페이지를 교체합니다.
- 간단하고, 초기화 코드에 대해 적절한 방법이다.
- 페이지가 올라온 순서를 큐에 저장합니다.
- 최적(Optimal) 페이지 교체
- 앞으로 가장 오랫동안 사용되지 않을 페이지를 교체하는 알고리즘
- 가장 최적의 방법
- 프로세스가 앞으로 사용할 페이지를 미리 알아야 한다는 선행조건이 필요하며 불가능
- LRU(least-recently-used)
- 가장 오래 사용되지 않은 페이지를 교체하는 알고리즘
- OPT 알고리즘보다 페이지 교체 횟수가 높지만 FIFO 알고리즘 보다 효율적
- LFU(least-frequently-used)
- 참조 횟수가 가장 작은 페이지를 교체하는 알고리즘
- MFU(most-frequently-used)
- FU 알고리즘과 반대로, 참조 횟수가 가장 많은 페이지를 교체하는 알고리즘
가상 메모리
운영체제에서 메모리 관리 기법의 하나로, 실제 물리적 메모리(RAM)보다 더 많은 메모리를 사용하는 것처럼 보이게 하는 시스템이다 를 통해 운영체제는 프로그램이 사용할 수 있는 메모리 용량을 물리적 메모리 크기와 관계없이 확장할 수 있게 된다.
언어
C
malloc()
malloc() 함수는 지정된 크기의 메모리를 동적으로 할당하고, 할당된 메모리의 포인터를 반환한다. 할당된 메모리는 초기화되지 않은 상태이다.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr;
int n = 5;
// 메모리 할당
arr = (int *)malloc(n * sizeof(int));
if (arr == NULL) {
printf("Memory allocation failed\n");
return 1; // 오류 처리
}
// 메모리 사용
for (int i = 0; i < n; i++) {
arr[i] = i * 10; // 예시로 값 초기화
printf("%d ", arr[i]);
}
printf("\n");
// 메모리 해제
free(arr);
return 0;
}
calloc()
calloc() 함수는 메모리를 할당하면서 초기화도 함께 해주는 함수이다. 첫 번째 인자는 할당할 요소의 개수이고, 두 번째 인자는 각 요소의 크기이다.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr;
int n = 5;
// 메모리 할당 및 초기화
arr = (int *)calloc(n, sizeof(int));
if (arr == NULL) {
printf("Memory allocation failed\n");
return 1; // 오류 처리
}
// 메모리 사용
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]); // 모든 값이 0으로 초기화됨
}
printf("\n");
// 메모리 해제
free(arr);
return 0;
}
realloc()
realloc() 함수는 이미 할당된 메모리의 크기를 변경하는 데 사용된다. 새로운 크기가 더 크거나 작을 수 있으며, 필요에 따라 새로운 메모리 블록이 할당된다.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr;
int n = 5;
// 메모리 할당
arr = (int *)malloc(n * sizeof(int));
if (arr == NULL) {
printf("Memory allocation failed\n");
return 1; // 오류 처리
}
// 메모리 사용
for (int i = 0; i < n; i++) {
arr[i] = i * 10;
}
// 메모리 크기 변경
n = 10;
arr = (int *)realloc(arr, n * sizeof(int));
if (arr == NULL) {
printf("Memory reallocation failed\n");
return 1; // 오류 처리
}
// 새로운 메모리 사용
for (int i = 5; i < n; i++) {
arr[i] = i * 10; // 새로운 값 초기화
}
// 출력
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
// 메모리 해제
free(arr);
return 0;
}
free()
free() 함수는 동적으로 할당된 메모리를 해제하는 데 사용된다. 해제를 하지 않으면 메모리 누수가 발생할 수 있다.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr;
int n = 5;
// 메모리 할당
arr = (int *)malloc(n * sizeof(int));
if (arr == NULL) {
printf("Memory allocation failed\n");
return 1; // 오류 처리
}
// 메모리 사용
for (int i = 0; i < n; i++) {
arr[i] = i + 1;
}
// 메모리 해제
free(arr);
arr = NULL; // 포인터를 NULL로 설정하여 dangling pointer 방지
return 0;
}
JAVA
추상클래스 vs 인터페이스
- 공통점
- new 연산자로 인스턴스 생성 불가능
- 사용하기 위해서는 하위 클래스에서 확장/구현 해야 한다.
- 차이점
| 구분 | 추상클래스 | 인터페이스 |
|---|---|---|
| 상속/구현 관계 | 단일 상속만 가능 (extends 사용) |
다중 구현 가능 (implements 사용) |
| 멤버의 구성 | 추상 메서드와 일반 메서드 모두 가질 수 있다. | 기본적으로 추상 메서드만 가질 수 있으나, Java 8 이후부터 default 메서드와 static 메서드도 포함 가능 |
| 변수 | static, final이 아닌 일반 변수 선언이 가능 |
모든 필드는 public static final로 암묵적으로 선언됨 |
| 접근 제어자 | 메서드와 필드에 다양한 접근 제어자 사용 가능 | 모든 메서드와 필드는 암묵적으로 public으로 선언됨 |
| 객체 생성 | 객체를 직접 생성할 수 없다. (단, 생성자를 가질 수 있음) | 객체를 생성할 수 없다. (생성자 자체를 가질 수 없음) |
| 목적 | 클래스 간의 공통된 기능을 정의하거나, 상속 계층을 설계하는 데 사용 | 클래스가 구현해야 할 규격(계약)을 정의하는 데 사용 |
싱글톤 패턴(Singleton Pattern)
싱글톤 패턴은 단 하나의 인스턴스를 생성해 사용하는 디자인 패턴
인스턴스가 1개만 존재해야 한다는 것을 보장하고 싶은 경우와 동일한 인스턴스를 자주 생성해야 하는 경우에 주로 사용. (메모리 낭비 방지)
Spring의 Bean이 대표적인 경우이다.
가비지 컬렉션(Garbage Collection)
시스템에서 동적으로 할당됐던 메모리 영역 중에서 필요없어진 메모리 영역을 회수하여 메모리를 관리해주는 기법
-
JVM이 어플리케이션의 실행을 잠시 멈추고, GC를 실행하는 쓰레드를 제외한 모든 쓰레드들의 작업을 중단 후 (Stop The World 과정)
-
사용하지 않는 메모리를 제거(Mark and Sweep 과정)하고 작업이 재개
new String()과 리터럴(“”)
new String()은 new 키워드로 새로운 객체를 생성하기 때문에 Heap 메모리 영역에 저장되며 변경가능하다""는 Heap 안에 있는 String Constant Pool 영역에 저장된다.자바에서는 문자열 리터럴을 상수 풀에 저장하여, 동일한 값을 가진 문자열 리터럴이 여러 번 생성되지 않도록 최적화한다.- 모두 변경 불가능한(immutable) 객체이다.
예시
String str = new String("hello");
str = "world"; // 새로운 String 객체를 할당
위 코드에서 str의 값은 변경되지 않는다. 대신 “world”라는 새로운 String 객체가 할당된다.
String, StringBuffer, StringBuilder
String, StringBuffer, StringBuilder
String은 불변 객체로, 문자열 수정 시 새로운 객체가 생성된다.StringBuffer는 가변 객체로, 문자열 수정 시 내부 배열을 재사용하며, 멀티 스레드 환경에서 안전하다.StringBuilder는StringBuffer와 유사하지만, 멀티 스레드 환경에서 안전하지 않다. 대신, 성능이 더 우수하다.
String
String 클래스는 불변(immutable) 객체이다. 즉, String 객체의 값을 변경할 수 없다. 문자열을 수정하려면 새로운 String 객체가 생성된다. 이러한 특성으로 인해 String은 문자열의 값이 자주 변경되지 않는 경우에 적합하다. String 객체는 상수 풀(String Constant Pool)에 저장될 수 있어, 동일한 문자열을 여러 번 사용할 때 메모리를 절약할 수 있다.
StringBuffer
StringBuffer 클래스는 가변(mutable) 객체이다. 즉, 문자열의 값을 변경할 수 있다. 문자열을 추가하거나 수정하는 작업을 할 때 StringBuffer는 내부 배열을 재사용하여 새로운 객체를 만들지 않기 때문에 성능이 좋다. StringBuffer는 멀티 스레드 환경에서도 안전하게 사용할 수 있도록 설계되어 있다. 다만, 멀티 스레드 환경이 아닌 경우에는 성능에 큰 차이가 나지 않기 때문에, 불필요한 동기화 작업을 피할 수 있다.
StringBuilder
StringBuilder 클래스는 StringBuffer와 매우 유사하지만, 스레드 안전성을 보장하지 않는다. 즉, 멀티 스레드 환경에서의 동기화가 필요하지 않은 경우에는 StringBuilder가 성능 면에서 StringBuffer보다 유리하다. 문자열을 자주 수정하는 작업에서는 StringBuilder가 더 효율적이다.
Inner Class(내부 클래스)와 Outer Class(외부클래스)
Inner Class(내부 클래스)와 Outer Class(외부 클래스)는 자바에서 클래스 간의 관계를 정의하는 중요한 개념이다. 내부 클래스는 외부 클래스의 구성 요소로 정의되며, 외부 클래스의 인스턴스나 정적 멤버에 접근할 수 있다.
- Outer Class(외부 클래스): 독립적인 클래스로, 내부 클래스의 선언을 포함할 수 있다.
- Inner Class(내부 클래스): 외부 클래스의 인스턴스나 정적 멤버에 접근할 수 있으며, 여러 종류로 나뉜다. (인스턴스 내부 클래스, 정적 내부 클래스, 지역 내부 클래스, 익명 내부 클래스 등)
내부 클래스는 외부 클래스와의 관계를 더욱 긴밀하게 만들어 주며, 객체 지향적인 설계를 보다 명확하고 깔끔하게 할 수 있다.
- 내부 클래스는 외부 클래스의 멤버에 접근할 수 있다.
- 외부 클래스는 내부 클래스의 객체를 생성하여 사용할 수 있다.
- 내부 클래스는 외부 클래스의 인스턴스나 정적 멤버에 접근할 수 있지만, 외부 클래스의 인스턴스를 명시적으로 생성할 필요는 없다.
- 정적 내부 클래스는 외부 클래스의 정적 멤버에만 접근할 수 있다.
Outer Class(외부 클래스)
외부 클래스는 자바에서 일반적인 클래스이다. 클래스 선언은 class 키워드를 사용하여 이루어지며, 내부 클래스가 포함될 수 있는 클래스이다. 외부 클래스는 독립적으로 존재하며, 다른 클래스와의 관계에 따라 내부 클래스를 사용할 수 있다.
Inner Class(내부 클래스)
내부 클래스는 다른 클래스의 내부에 정의된 클래스로, 외부 클래스의 인스턴스나 정적 멤버에 접근할 수 있는 특성을 가진다. 내부 클래스는 인스턴스 내부 클래스, 정적 내부 클래스, 지역 내부 클래스, 익명 내부 클래스 등 여러 종류로 나뉜다.
1. 인스턴스 내부 클래스 (Instance Inner Class) 인스턴스 내부 클래스는 외부 클래스의 인스턴스가 생성된 후에 사용할 수 있다. 이 클래스는 외부 클래스의 인스턴스 멤버에 접근할 수 있다.
class OuterClass {
private String outerField = "Outer class field";
class InnerClass {
void display() {
System.out.println(outerField); // 외부 클래스의 인스턴스 멤버에 접근
}
}
}
InnerClass는 OuterClass의 인스턴스를 통해서만 사용할 수 있다.
2. 정적 내부 클래스 (Static Inner Class) 정적 내부 클래스는 외부 클래스의 인스턴스와 관계없이 정적 멤버로 정의된다. 이 클래스는 외부 클래스의 인스턴스 멤버에는 접근할 수 없지만, 외부 클래스의 정적 멤버에는 접근할 수 있다.
class OuterClass {
private static String staticOuterField = "Static outer class field";
static class StaticInnerClass {
void display() {
System.out.println(staticOuterField); // 외부 클래스의 정적 멤버에 접근
}
}
}
StaticInnerClass는 OuterClass의 인스턴스를 만들지 않고도 사용할 수 있다.
3. 지역 내부 클래스 (Local Inner Class) 지역 내부 클래스는 메서드 내부에 정의된 클래스이다. 이 클래스는 메서드 내에서만 사용할 수 있으며, 메서드의 로컬 변수나 매개변수에 접근할 수 있다.
class OuterClass {
void outerMethod() {
class LocalInnerClass {
void display() {
System.out.println("Local inner class");
}
}
LocalInnerClass localInner = new LocalInnerClass();
localInner.display();
}
}
LocalInnerClass는 outerMethod() 메서드 내에서만 사용될 수 있다.
4. 익명 내부 클래스 (Anonymous Inner Class) 익명 내부 클래스는 이름이 없는 클래스로, 보통 클래스의 인스턴스를 만들 때 바로 정의하여 사용하는 방식이다. 주로 인터페이스나 추상 클래스를 구현할 때 사용된다.
class OuterClass {
void outerMethod() {
Runnable r = new Runnable() {
public void run() {
System.out.println("Anonymous inner class");
}
};
r.run();
}
}
익명 내부 클래스는 즉시 객체를 생성하고 메서드 내에서 바로 사용할 수 있다.
Error, Exception, CheckedException, UnCheckedException
Optional API
NPE(NullPointerException)위한 복잡한 처리 로직을 Java8 부터 Optional
final / finally / finalize 키워드 부분
-
final은 클래스, 메소드, 변수, 인자를 선언할 때 사용할 수 있으며, 한 번만 할당하고 싶을 때 사용한다.- final 변수는 한 번 초기화되면 그 이후에 변경할 수 없다.
- final 메소드는 다른 클래스가 이 클래스를 상속할 때 메소드 오버라이딩을 금지한다.
- final 클래스는 다른 클래스에서 이 클래스를 상속할 수 없다.
-
finally는 try-catch와 함께 사용되며, try-catch가 종료될 때 finally block이 항상 수행되기 때문에 마무리 해줘야 하는 작업이 존재하는 경우에 해당하는 코드를 작성해주는 코드 블록이다. -
finalize는 Object 클래스에 정의되어 있는 메소드이며, GC에 의해 호출되는 메소드로 절대 호출해서는 안되는 메소드이다. GC가 발생하는 시점이 불분명하기 때문에 해당 메소드가 실행된다는 보장이 없고, finalize() 메소드가 오버라이딩 되어 있으면 GC가 이루어질 때 바로 Garbage Collectiong 되지 않는다. GC가 지연되면서 OOME(Out of Memory Exception)이 발생할 수 있기 때문에 finalize() 메소드를 오버라이딩하여 구현하는 것을 권장하지 않다.
try-with-resources
: 부적으로 finally처럼 동작해서, 예외가 터지든 말든 무조건 close()를 실행해준다.
AutoCloseable 인터페이스 구현 객체만 가능하다
가비지 컬렉션(Garbage Collection)
VM의 메모리 관리 기법 중 하나로 시스템에서 동적으로 할당됐던 메모리 영역 중에서 필요없어진 메모리 영역을 회수하여 메모리를 관리해주는 기법
GC의 작업을 수행하기 위해 JVM이 어플리케이션의 실행을 잠시 멈추고, GC를 실행하는 쓰레드를 제외한 모든 쓰레드들의 작업을 중단 후 (Stop The World 과정) 사용하지 않는 메모리를 제거(Mark and Sweep 과정)하고 작업 재개
웹(백엔드 중심으로)
Restful API
HTTP 통신을 Rest 설계 규칙을 잘 지켜서 개발한 API
-
REST(REpresentational State Transfer) 설계
정의- 자원을 이름으로 구분하여 자원의 상태(정보)를 주고 받는 것=> 자원의 표현에 의한 상태 전달
- HTTP 프로토콜에서 웹의 장점 활용에 유리한 아키텍처 스타일이다.
- CRUD(Create, Read, Update, Delete) 연산을 수행하기 위해 URI(Resource)로 GET, POST 등의 방식(Method)을 사용하여 요청을 보낸다.
- URI는 정보의 자원만 표현해야 하며, 자원의 상태와 행위는 HTTP Method에 명시하는 형식이다.
구성요소- 자원(Resource) - URI
- 행위(Verb) - Method
- 표현 ( Representation of Resource ) - JSON, XML, TEXT, RSS
특징- Server-Client (서버-클라이언트 구조)
- Stateless (무상태)
- Cacheable (캐시 처리 기능) : Last-Modified Tag 또는 E-Tag를 이용해 캐싱을 구현
- Layered System (계층 구조)
- 보안, 로드 밸런싱, 암호화 등을 위한 계층을 추가하여 구조를 변경할 수 있습니다.
- Proxy, Gateway와 같은 네트워크 기반의 중간매체를 사용할 수 있습니다.
- Client는 Server와 직접 통신하는지, 중간 서버와 통신하는지는 알 수 없습니다. 5. Uniform Interface (인터페이스 일관성) : Loosely Coupling(느슨한 결함) 형태를 갖게되어 특정 언와 기술에 종속되지 않는다.
- Self-Descriptiveness (자체 표현)
- 요청 메시지만 보고도 이해가 가능한 자체 표현 구조이다.
-
REST API
정의- REST의 특징을 기반으로 서비스 API를 구현한 것
특징- 각 요청이 어떤 동작이나 정보를 위한 것인지를 그 요청의 모습 자체로 추론이 가능한 것
주의사항- URI는 정보의 자원을 표현해야 한다.
- 자원에 대한 행위는 HTTP Method(GET, POST, PUT, PATCH, DELETE)로 표현한다(행위는 URI에 포함시키지 않는다.)
- URI는 명사를 사용한다.(리소스명은 동사가 아닌 명사를 사용해야 한다.)
- 슬래시( / )로 계층 관계를 표현한다.
- URI 마지막 문자로 슬래시 ( / )를 포함하지 않는다.
- 밑줄( _ )을 사용하지 않고, 하이픈( - )을 사용한다.
- URI는 소문자로만 구성한다.
- HTTP 응답 상태 코드 사용
- 파일확장자는 URI에 포함하지 않는다.
URI, URL, URN
- URI (Uniform Resource Identifier)
- 정의: URI는 인터넷 상의 자원을 식별하는 모든 문자열을 의미한다. 자원의 위치나 이름을 통해 자원을 식별할 수 있다.
- 구성 요소: URI는 URL과 URN 두 가지 방식으로 자원을 식별할 수 있다.
- 예시:
https://www.example.com/page(URL),urn:isbn:0451450523(URN) - 정리: URI는 자원의 이름 또는 위치를 통해 식별하는 모든 문자열을 포괄하는 개념이다.
- URL (Uniform Resource Locator)
- 정의: URL은 자원의 “위치”를 나타내며, 자원에 접근하는 방법(프로토콜)과 위치 정보가 포함된다.
- 구성 요소: 프로토콜(
https://), 도메인(www.example.com), 경로(/page) - 예시:
https://www.example.com/page - 정리: URL은 특정 자원의 위치와 접근 경로를 제공하는 문자열로, 주소의 역할을 한다.
- URN (Uniform Resource Name)
- 정의: URN은 자원의 “이름”을 사용해 자원을 식별한다. 특정 위치와 상관없이 자원 자체를 고유하게 식별하는 역할을 한다.
- 구성 요소:
urn:<이름공간>:<이름>형식을 따른다. - 예시:
urn:isbn:0451450523(ISBN을 통해 특정 책을 식별) - 정리: URN은 위치와 무관하게 자원의 고유한 이름을 통해 자원을 식별한다.
요약: URI, URL, URN의 관계
- URI: 자원을 식별하는 모든 문자열을 포함하는 개념 (URL과 URN을 포함)
- URL: 자원의 위치를 나타내는 URI
- URN: 자원의 고유한 이름을 나타내는 URI
모든 URL과 URN은 URI이지만, URL과 URN은 서로 다른 역할을 한다.
CORS(교차 출처 리소스 공유, Cross-Origin Resource Sharing)
- 도메인이 서로다른 2개의 사이트가 데이터를 주고 받을 때 다른 도메인에 대하여 허가하지 않는 브라우저 정책
- “출처 (Origin)”는, url에서 Protocol, Host, Port 까지를 의미한다.
CSRF(Cross-site request forgery)
사용자가 의도치 않은 요청을 특정 웹 애플리케이션에 보내게 함으로써 악의적인 행위를 수행하는 웹 보안 취약점이다. CSRF는 사용자가 이미 인증된 상태라는 점을 악용하며, 사용자가 모르게 서버에 요청을 보내도록 만들어 공격자가 원하는 행동을 수행하게 만든다.
인증 vs 인가
웹 개발의 관점에서 인증은 사용자가 누구인지 확인하는 과정이다. 사용자가 자신의 신원을 증명하기 위해 제공하는 자격 증명(예: 아이디와 비밀번호, OAuth 토큰, 인증서 등)을 서버가 검증하여 사용자를 식별한다. 인증은 “이 사용자가 실제로 주장하는 사람인가?”를 확인하는 데 초점이 맞춰져 있다.
반면 인가는 인증이 완료된 사용자가 시스템 내에서 특정 자원이나 기능에 접근할 권한이 있는지 확인하는 과정이다. 예를 들어, 인증된 사용자가 관리자 페이지에 접근하거나 데이터베이스의 특정 데이터를 수정할 수 있는 권한이 있는지를 확인한다. 인가는 “이 사용자가 특정 작업을 수행하거나 자원에 접근할 권리가 있는가?”를 판단하는 데 중점을 둔다.
예시
- 인증: 사용자가 웹 애플리케이션에 로그인할 때 아이디와 비밀번호를 입력하여 본인이 등록된 사용자임을 증명하는 단계.
- 인가: 로그인 후, 사용자가 관리자 계정으로 접근 가능한 페이지나 특정 기능(예: 데이터 삭제, 설정 변경)에 접근할 수 있는 권한이 있는지를 확인하는 단계.
인증은 보통 AuthN(Authentication)이라고 표현되고, 인가는 AuthZ(Authorization)으로 약칭된다.
인증이 인가를 선행하며, 인증 없이는 인가 과정을 진행할 수 없다.
웹 서버란? NGINX와 Apache 비교
웹 서버는 클라이언트(브라우저)의 요청을 받아 HTML, 이미지, CSS, JS 등의 정적 파일 또는 동적 콘텐츠(백엔드 실행 결과)를 제공하는 소프트웨어다.
NGINX와 Apache 비교
| 항목 | NGINX | Apache |
|---|---|---|
| 처리 방식 | 비동기 이벤트 기반 (비차단 I/O) | 멀티 프로세스 또는 멀티 스레드 기반 |
| 성능 | 높은 동시성 처리에 강함 (수천 연결 유지 가능) | 연결 수 많아질수록 성능 저하 가능 |
| 정적 파일 처리 | 매우 빠름 | 느린 편 |
| 설정 파일 | 간결 (nginx.conf) |
유연하고 다양한 디렉티브 (.htaccess 지원) |
| 사용 예시 | 리버스 프록시, API 게이트웨이, CDN | 전통적인 LAMP 스택 (Linux, Apache, MySQL, PHP) |
| 모듈 구조 | 컴파일 시 모듈 포함 (동적 로딩 제한적) | 런타임에 모듈 로딩 가능 (유연함) |
| 리버스 프록시 | 기본 기능으로 탁월 | 별도 설정 필요 |
Spring
Spring Filter와 Interceptor
필터
말 그대로 요청과 응답을 거른뒤 정제하는 역할을 한다. 스프링 컨테이너가 아닌 톰캣과 같은 웹 컨테이너에 의해 관리가 되는 것이고, 스프링 범위 밖에서 처리된다. Dispatcher Servlet에 요청이 전달되기 전/후에 url 패턴에 맞는 모든 요청에 대해 부가 작업을 처리할 수 있는 기능을 제공한다.
사용 사례 :
- 보안 및 인증/인가 관련 작업
- 모든 요청에 대한 로깅 또는 검사
- 이미지/데이터 압축 및 문자열 인코딩
- Spring과 분리되어야 하는 기능
인터셉터
요청에 대한 작업 전/후로 가로채 요청과 응답을 참조하거나 가공하는 역할을 한다. 웹 컨테이너에서 동작하는 필터와 달리 인터셉터는 스프링 컨텍스트에서 동작한다.Dispatcher Servlet이 Controller를 호출하기 전/후에 인터셉터가 끼어들어 요청과 응답을 참조하거나 가공할 수 있는 기능을 제공한다.
사용 사례 :
- 세부적인 보안 및 인증/인가 공통 작업
- API 호출에 대한 로깅 또는 검사
- Controller로 넘겨주는 정보(데이터)의 가공
- 인증된 사용자가 아니라면 /login 페이지로 리다이렉트하고, 인증되어 있다면 컨트롤러로 요청을 넘기는 등
컨테이너 vs 컨텍스트
스프링 컨테이너(Spring Container)와 스프링 컨텍스트(Spring Context)는 서로 관련 있는 개념이지만, 약간의 관점 차이가 있다.
| 항목 | 스프링 컨테이너 (Container) | 스프링 컨텍스트 (Context) |
|---|---|---|
| 의미 | 빈을 생성, 관리, 주입하는 전체 시스템 | 컨테이너의 구현체, 실제로 사용하는 객체 |
| 대상 | 개념적 시스템 전체 | ApplicationContext 등 실제 객체 |
| 관점 | 스프링 프레임워크가 제공하는 기능적인 틀 | 개발자가 사용하는 구체적인 API |
| 예시 | IoC 컨테이너, DI 컨테이너 | AnnotationConfigApplicationContext, WebApplicationContext 등 |
컨테이너는 스프링의 객체 관리 시스템 전체를 의미하고,
컨텍스트는 그 컨테이너의 구현체이자 개발자가 직접 사용하는 인터페이스이다.
즉, 컨텍스트는 컨테이너의 일종이고,
우리는 일반적으로 ApplicationContext라는 이름의 컨테이너(=컨텍스트)를 사용한다고 이해하면 된다.
Lombok
Lombok은 메소드를 컴파일 하는 과정에 개입해서 추가적인 코드를 만들어낸다. 이것을 어노테이션 프로세싱이라고 하는데, 어노테이션 프로세싱은 자바 컴파일러가 컴파일 단계에서 어노테이션을 분석하고 처리하는 기법을 말한다. (Lombok 라이브러리를 추가할 때 CompileOnly, AnnotationProcessor를 추가하는 이유도 된다.)
VO, BO, DAO, DTO
- DAO(Data Access Object) DB의 데이터에 접근을 위한 객체를 말gks다. (Repository 또는 Mapper에 해당)
- BO(Business Object) 여러 DAO를 활용해 비즈니스 로직을 처리하는 객체를 말한다. (Service에 해당)
- DTO(Data Transfer Object) 각 계층간의 데이터 교환을 위한 객체를 말한다.
- (여기서 말하는 계층은 Controller, View, Business Layer, Persistent Layer)
- VO (Value Object) 실제 데이터만을 저장하는 객체를 말한다.
N+1 문제
N+1이란 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것을 의미한다. Fetch Join을 사용해 해결하는 방법이 유명하다. N+1 문제가 발생하는 이유는 연관관계를 가진 엔티티를 조회할 때 한 쪽 테이블만 조회하고 연결된 다른 테이블은 따로 조회하기 때문인데,Fetch Join을 사용하면 미리 두 테이블을 Join하여 한 번에 모든 데이터를 가져오기 때문에 N+1문제를 애초에 막을 수 있다.
가변객체와 불변객체
가변 객체 (Mutable Object)
가변 객체는 객체의 상태가 생성 후에도 변경이 가능한 객체를 의미한다. 즉, 객체의 필드 값이나 내부 상태를 변경할 수 있는 객체이다.
불변 객체 (Immutable Object)
불변 객체는 객체의 상태가 한 번 설정되면 변경할 수 없는 객체를 의미한다. 즉, 객체가 생성된 후에는 객체의 필드나 상태를 변경할 수 없다. 모든 값은 final로 선언되며, 객체가 불변 상태로 유지되도록 한다.
영속성 컨텍스트(Persistence Context)
PA(Java Persistence API)에서 엔티티 객체를 관리하는 환경을 말한다. 영속성 컨텍스트는 데이터베이스와의 상호작용을 효율적으로 처리하기 위해, 엔티티 객체들의 상태를 관리하고, 이를 통해 데이터베이스와의 동기화가 원활히 이루어지도록 돕는다.
JPA를 사용하면서 쿼리가 복잡해지는 경우
- JPQL과 Querydsl을 사용
종합& 기타
Framework vs Library
- 개발자의 제어권을 프레임워크에게 넘김으로써 신경써야할 것을 줄일 수 있는데,이를 제어의 역전(Inversion of Control)이라한다.
Call By Value vs Call By Reference
- Call By Value(값에 의한 호출) - 인자로 받은 값을 복사하여 처리하는 방식
- Call By Reference(참조에 의한 호출) - 인자로 받은 값의 주소를 참조하여 직접 저장해 값에 영향을 주는 방식
- Java는 모두 콜 바이 벨류이다.
절차지향 vs 객체지향
- 절차지향
- 순차적인 처리를 중요시하는 프로그래밍 기법
- 객체지향
- 실제 세계의 사물들을 객체로 모델링하여 개발을 진행하는 프로그래밍 기법
- 누가 어떤 일을 할 것인가?”가 핵심
객체지향 프로그래밍 (OOP)
객체지향 프로그래밍(Object-Oriented Programming, OOP)은 소프트웨어 개발 방법론 중 하나로, 프로그램을 객체라는 단위로 나누어 설계하고 구현하는 방식이다. 객체는 상태(state)와 행동(behavior)을 가지며, 이를 통해 현실 세계를 모델링한다. OOP는 코드의 재사용성과 유지보수성을 높이기 위해 고안되었다.
OOP의 주요 개념
- 객체 (Object): 상태와 행동을 가진 독립적인 단위. 객체는 클래스의 인스턴스이며, 상태는 속성(attribute)으로, 행동은 메서드(method)로 표현된다.
- 클래스 (Class): 객체의 청사진(설계도). 클래스는 객체의 속성과 메서드를 정의하며, 객체는 클래스로부터 생성된다.
- 상속 (Inheritance): 기존 클래스로부터 새로운 클래스를 생성하는 기능. 상위 클래스(부모 클래스)의 속성과 메서드를 하위 클래스(자식 클래스)가 상속받아 재사용할 수 있다.
- 다형성 (Polymorphism): 동일한 메서드 이름이지만 서로 다른 객체에 대해 다양한 방식으로 동작하는 기능. 이는 오버로딩(overloading)과 오버라이딩(overriding)으로 구현할 수 있다.
- 캡슐화 (Encapsulation): 객체의 상태를 외부에서 직접 접근하지 못하도록 보호하는 기능. 객체 내부의 데이터와 메서드를 하나로 묶고, 접근 제어를 통해 데이터 보호를 구현한다.
OOP의 원칙
-
캡슐화
데이터(필드)와 이를 조작하는 메서드를 하나의 단위로 묶고, 외부에서 접근을 제한하여 객체 내부의 상태를 보호하는 것이다. 주로 접근 제어자(private,protected,public)를 사용하여 구현한다. -
상속
기존 클래스를 재사용하여 새로운 클래스를 만드는 것이다. 코드의 재사용성을 높이고, 계층 구조를 통해 확장성을 제공한다.extends키워드를 사용하여 구현한다. -
다형성
동일한 인터페이스나 상위 클래스를 공유하는 객체들이 각자의 방식으로 동작하도록 하는 것이다. 메서드 오버라이딩과 메서드 오버로딩을 통해 구현된다. 주로 실행 시 동적 바인딩을 통해 이루어진다. -
추상화
불필요한 세부 정보를 숨기고, 객체의 핵심적인 특징만 표현하는 것이다. 추상 클래스(abstract)나 인터페이스를 사용하여 구현한다. 이를 통해 객체의 행동(메서드)만 정의하고 구체적인 구현은 서브클래스에서 제공하도록 한다.
SOLID 원칙
SOLID 원칙은 객체지향 설계를 위한 다섯 가지 원칙을 의미하며, 코드의 가독성과 유지보수성을 높이는 데 도움을 준다.
- S - Single Responsibility Principle (SRP):
- 클래스는 하나의 책임만 가져야 하며, 그 책임을 완전히 캡슐화해야 한다. 즉, 클래스는 하나의 기능만 수행해야 하며, 기능 변경 시 해당 클래스만 수정하면 되도록 설계해야 한다.
- O - Open/Closed Principle (OCP):
- 소프트웨어 개체는 확장에는 열려 있어야 하고, 수정에는 닫혀 있어야 한다. 즉, 기존 코드를 수정하지 않고 새로운 기능을 추가할 수 있어야 한다. 이를 위해 인터페이스나 추상 클래스를 사용하여 확장을 용이하게 한다.
- L - Liskov Substitution Principle (LSP):
- 서브타입은 언제나 부모 타입으로 교체할 수 있어야 하며, 프로그램의 정확성이 유지되어야 한다. 즉, 자식 클래스는 부모 클래스의 모든 기능을 대체할 수 있어야 하며, 이로 인해 사용자에게 예기치 않은 결과를 초래해서는 안 된다.
- I - Interface Segregation Principle (ISP):
- 클라이언트는 자신이 사용하지 않는 메서드에 의존하지 않도록 여러 개의 구체적인 인터페이스로 나누어야 한다. 즉, 큰 인터페이스보다는 작은 인터페이스를 여러 개 만들어 필요한 메서드만을 포함하는 것이 좋다.
- D - Dependency Inversion Principle (DIP):
- 고수준 모듈은 저수준 모듈에 의존해서는 안 되며, 두 모듈 모두 추상화에 의존해야 한다. 즉, 구체적인 구현체에 의존하지 않고 인터페이스나 추상 클래스에 의존함으로써 결합도를 낮추어야 한다.
객체지향의 장점
- 코드 재사용성: 상속과 다형성을 통해 기존의 코드를 재사용할 수 있어 개발 시간을 단축할 수 있다.
- 유지보수 용이성: 캡슐화를 통해 객체의 내부 구현을 숨길 수 있어, 변경 사항이 있을 때 다른 부분에 미치는 영향을 최소화할 수 있다.
- 모델링의 용이성: 현실 세계의 개념을 객체로 모델링하여 문제를 보다 직관적으로 이해하고 해결할 수 있다.
- 유연성: 다형성을 통해 서로 다른 클래스의 객체를 동일한 방법으로 처리할 수 있어, 시스템 확장이 용이하다.
객체지향의 단점
- 복잡성 증가: 객체지향 설계는 객체 간의 관계와 상속 구조가 복잡해질 수 있으며, 이로 인해 이해하고 관리하기 어려워질 수 있다.
- 성능 문제: 객체를 생성하고 관리하는 데 추가적인 메모리와 시간이 소요되며, 특히 대규모 애플리케이션에서는 성능 저하를 초래할 수 있다.
- 과도한 추상화: 객체지향 설계에서 지나치게 추상화하면 오히려 코드가 복잡해져 가독성이 떨어질 수 있다. 설계를 간단하게 유지하는 것이 중요하다.
- 학습 곡선: OOP의 개념과 원칙을 이해하고 적용하는 데 시간이 필요할 수 있으며, 특히 초보자에게는 진입 장벽이 높을 수 있다.
결론
객체지향 프로그래밍은 소프트웨어 개발에서 매우 중요한 패러다임으로, 잘 설계된 OOP 시스템은 높은 코드 재사용성과 유지보수성을 제공한다. SOLID 원칙은 이러한 객체지향 설계를 개선하기 위한 지침을 제공하며, 각 원칙을 지키면서 설계를 진행하면 더 나은 품질의 소프트웨어를 개발할 수 있다. 그러나 OOP의 장점과 단점을 잘 이해하고, 상황에 맞게 적절하게 적용하는 것이 중요하다.
얕은 복사(Shallow Copy)와 깊은 복사(Deep Copy)
얕은 복사(Shallow Copy)
- 복사 대상 객체의 참조(Reference)만 복사
- 원본과 복사본이 동일한 메모리를 참조하게 되어, 한쪽의 변경이 다른 쪽에도 영향을 미친다.
깊은 복사(Deep Copy)
- 복사 대상 객체의 모든 데이터를 별도의 메모리에 복사
- 원본과 복사본이 독립적인 객체가 되어, 한쪽의 변경이 다른 쪽에 영향을 주지 않는다.
메모리영역(Memory Segments)
프로그램이 실행될 때, 운영체제는 메모리를 여러 영역으로 나누어 관리한다. 이러한 메모리 영역은 각각의 용도에 맞게 사용되며, 주로 코드, 데이터, 힙, 스택으로 나뉜다. 각 영역의 특성과 용도를 자세히 살펴보자.
1. 코드 영역 (Code Segment)
- 정의: 코드 영역은 프로그램의 실행 코드가 저장되는 메모리 공간이다. 이 영역은 읽기 전용으로 설정되어 있어, 실행 중에 코드가 수정되지 않도록 보호된다.
- 특징:
- 불변성: 코드 영역은 프로그램이 실행되는 동안 변경되지 않으며, 보통 프로그램의 바이너리 파일에서 로드된다.
- 디버깅 정보: 일부 경우, 코드 영역에는 디버깅 정보를 포함할 수 있어 개발자가 프로그램을 테스트하고 디버깅하는 데 도움이 된다.
- 메모리 할당: 운영체제가 프로그램을 메모리에 로드할 때 자동으로 할당된다.
2. 데이터 영역 (Data Segment)
- 정의: 데이터 영역은 프로그램이 사용하는 전역 변수 및 정적 변수를 저장하는 메모리 공간이다. 데이터 영역은 프로그램이 시작될 때 초기화되며, 실행 동안 지속된다.
- 특징:
- 초기화된 데이터: 초기화된 전역 변수 및 정적 변수가 이 영역에 저장된다.
- 비초기화된 데이터: 초기값이 없는 전역 변수도 포함된다. 이 경우, 자동으로 0으로 초기화된다.
-
메모리 할당: 프로그램이 시작될 때 운영체제가 자동으로 할당한다.
-
데이터 영역의 구조
- Initialized Data Segment: 초기화된 변수들이 저장되는 부분이다.
- Uninitialized Data Segment (BSS): 초기화되지 않은 변수들이 저장되는 부분으로, 0으로 초기화된다.
3. 힙 영역 (Heap Segment)
- 정의: 힙 영역은 동적으로 할당되는 메모리 공간으로, 런타임 중에 크기가 변경될 수 있는 메모리 블록을 저장한다.
- 특징:
- 동적 메모리 할당: 프로그래머가 필요한 만큼 메모리를 요청하고, 사용이 끝난 후 해제해야 한다. 이 작업은
malloc,calloc,realloc,free와 같은 함수를 통해 수행된다. - 크기 가변성: 힙 영역의 크기는 프로그램 실행 중에 필요에 따라 늘리거나 줄일 수 있다.
- 메모리 누수: 힙에서 할당된 메모리를 해제하지 않으면 메모리 누수가 발생할 수 있다.
- 동적 메모리 할당: 프로그래머가 필요한 만큼 메모리를 요청하고, 사용이 끝난 후 해제해야 한다. 이 작업은
- 메모리 할당: 프로그래머가 명시적으로 요청하며, 운영체제가 이를 관리한다.
4. 스택 영역 (Stack Segment)
- 정의: 스택 영역은 함수 호출 및 지역 변수를 저장하는 메모리 공간이다. 스택은 LIFO(Last In, First Out) 구조로 관리된다.
- 특징:
- 지역 변수: 함수 내에서 선언된 지역 변수와 매개변수가 이 영역에 저장된다.
- 함수 호출: 함수 호출 시, 스택에 호출 정보를 저장하고, 함수가 종료되면 해당 정보를 팝(pop)하여 복구한다.
- 자동 해제: 스택 영역의 메모리는 함수가 종료되면 자동으로 해제된다.
- 메모리 할당: 스택 메모리는 운영체제가 자동으로 관리하며, 프로그래머가 직접 메모리를 해제할 필요가 없다.
메모리 영역의 요약
- 코드 영역: 실행 코드 저장 (읽기 전용)
- 데이터 영역: 전역 및 정적 변수 저장 (초기화된 및 비초기화된)
- 힙 영역: 동적으로 할당되는 메모리 저장 (프로그래머에 의해 관리)
- 스택 영역: 함수 호출과 지역 변수 저장 (자동 관리)
이처럼 메모리 영역은 각각의 목적에 맞게 사용되며, 프로그램의 효율성과 안정성을 높이는 데 중요한 역할을 한다. 각 영역의 특징을 이해하고 적절히 사용하는 것이 소프트웨어 개발에서 매우 중요하다.
정적쿼리 vs 동적쿼리
동적 쿼리와 정적 쿼리는 데이터베이스에 쿼리를 전달하는 방식에서 차이가 있다. 각각의 개념과 특징은 다음과 같다.
- 정적 쿼리 (Static Query)
- 정의: 쿼리 내용이 고정되어 있는 쿼리로, 실행될 때마다 동일한 SQL 문을 사용한다.
- 특징:
- 쿼리가 고정된 상태로 컴파일되고 재사용된다.
- 성능이 안정적이며, SQL 인젝션 공격을 방지하기 쉽다.
- 쿼리를 미리 컴파일할 수 있어, 반복적으로 동일한 작업을 수행할 때 유리하다.
- 주로 Prepared Statement를 사용해 작성한다.
- 예:
SELECT * FROM Users WHERE user_id = ?;특정
user_id값만 변경하여 쿼리를 실행한다.
- 동적 쿼리 (Dynamic Query)
- 정의: 쿼리 내용이 동적으로 생성되어 실행되는 쿼리로, 특정 조건에 따라 SQL 문이 실행 시점에 변경될 수 있다.
- 특징:
- 쿼리 내용이 실행 시점에 생성되므로, 다양한 조건에 맞춰 유연하게 쿼리를 구성할 수 있다.
- 성능 측면에서는 정적 쿼리보다 느릴 수 있으며, SQL 인젝션 공격에 취약할 수 있다.
- 복잡한 검색 조건을 처리하거나, 동적으로 테이블이나 컬럼을 변경할 때 유용하다.
- 주로 Statement를 사용해 작성한다.
- 예:
String query = "SELECT * FROM Users WHERE 1=1"; if (userName != null) { query += " AND name = '" + userName + "'"; } if (userEmail != null) { query += " AND email = '" + userEmail + "'"; }userName과userEmail값에 따라 SQL 문이 달라진다.
요약
- 정적 쿼리는 SQL 문이 고정되어 성능이 안정적이며 보안성이 높다.
- 동적 쿼리는 실행 시점에 쿼리를 생성하여 유연하게 사용할 수 있지만, 성능 저하와 보안 문제에 주의해야 한다.
문자 인코딩
1. ASCII (American Standard Code for Information Interchange)
- 7비트로 구성되어 총 128개의 문자만 표현 가능
- 영어 알파벳, 숫자, 일부 특수문자만 지원
- 예:
A→ 65,a→ 97
2. Extended ASCII (ISO 8859-1, Latin-1 등)
- ASCII의 확장 버전으로 8비트(1바이트) 사용
- 유럽어 계열의 문자 지원 (예: ñ, ü 등)
- 총 256문자 표현 가능
3. Unicode
- 전 세계 모든 문자를 통합하려는 표준
- 모든 문자에 고유한 코드 포인트를 부여 (예:
U+AC00= 가) - 다양한 인코딩 방식으로 표현됨:
- UTF-8: 가변 길이 (1~4바이트), ASCII 호환, 전 세계에서 가장 많이 사용
- UTF-16: 고정 2바이트 or 4바이트 (서로게이트 사용)
- UTF-32: 4바이트 고정, 표현은 단순하지만 비효율적
- UTF-8 예시:
A→0x41(1바이트)가→0xEAB080(3바이트)
4. EUC-KR
- 한국어 인코딩 방식 중 하나
- 한글 2바이트로 표현, ASCII는 그대로 사용
- 예전 Windows, 인터넷 환경에서 널리 사용됨 (현재는 UTF-8로 대체되는 추세)
5. Shift-JIS
- 일본어를 표현하기 위한 문자 인코딩
- ASCII + 일본어(한자, 히라가나 등)를 혼합
6. ISO 2022, GB2312, Big5 등
- 국가별/지역별 문자 집합을 정의한 표준 인코딩
- 중국, 대만, 일본 등에서 각각 사용
요약
| 이름 | 바이트 수 | 특징 |
|---|---|---|
| ASCII | 7비트 | 영어 전용, 가장 단순 |
| UTF-8 | 1~4바이트 | 세계 표준, 유니코드 표현 방식 |
| UTF-16 | 2 or 4바이트 | 고정 길이, Windows 내부 표현 |
| EUC-KR | 1~2바이트 | 한국어 전용, 과거에 많이 사용 |
| Shift-JIS | 1~2바이트 | 일본어 전용 인코딩 |
| ISO 8859-1 | 1바이트 | 라틴 문자 확장 |
좋아, 아래에 두 질문에 대한 명확하고 실무 중심의 답변을 제공할게.
1. Base64 인코딩
Base64 인코딩은 이진 데이터를 ASCII 문자열 형식으로 변환하는 인코딩 방식이다.
주로 이진 데이터를 텍스트 기반 환경(HTML, JSON 등)에 안전하게 포함시키기 위해 사용된다.
- 3바이트(24비트)를 6비트씩 나눠 총 4개의 문자로 변환한다.
- 결과적으로 원본보다 약 33% 길어진다.
- 대표적인 사용 사례:
- 이메일 첨부파일 인코딩
- 이미지 데이터를 HTML/CSS 내에 인라인으로 삽입 (
<img src="data:image/png;base64,...">) - JWT(JSON Web Token)에서 Header, Payload 부분 인코딩
주의점: 보안 기능은 없으며, 단순히 인코딩일 뿐 암호화가 아니다. 중요한 정보 보호에는 적절하지 않다.
base64url 인코딩
일반 base64에서 사용하는 +, /, = 문자를 URL-safe하게 바꾼 버전 즉, 가볍게 인코딩한 텍스트일 뿐, 암호화는 아니다
Kubernetes
쿠버네티스(Kubernetes)를 처음 접하고 면접에서 잘 대답하려면, 핵심 개념과 자주 나오는 질문을 간단히 정리해본다.
-
쿠버네티스란?
쿠버네티스(K8s)는 컨테이너화된 애플리케이션을 자동으로 배포, 확장, 관리해주는 오픈소스 플랫폼이다.
도커 컨테이너처럼 애플리케이션을 감싸는 “컨테이너”를 다루기 위해 만들어졌다. - 주요 개념
- 컨테이너:
애플리케이션과 그 실행 환경을 포함하는 독립적인 패키지.
도커 컨테이너가 대표적이다. - 노드(Node):
컨테이너가 실행되는 서버(물리적 서버나 VM). - 파드(Pod):
쿠버네티스에서 관리되는 최소 실행 단위.
보통 한 개의 컨테이너를 포함하지만, 여러 개의 컨테이너를 포함할 수도 있다. - 클러스터(Cluster):
여러 노드가 모여 하나의 시스템처럼 작동하는 구조. - 마스터 노드(Master Node):
클러스터를 관리하고 제어하는 중심 역할. - 워크 노드(Worker Node):
실제로 애플리케이션 컨테이너가 실행되는 노드. - 디플로이먼트(Deployment):
애플리케이션의 배포와 업데이트를 관리하는 쿠버네티스 오브젝트. - 서비스(Service):
파드들이 네트워크를 통해 서로 통신하거나 외부와 연결되도록 하는 방법.
- 컨테이너:
- 기본적인 흐름
- 사용자가 쿠버네티스에 배포 요청.
- 쿠버네티스가 디플로이먼트를 생성.
- 디플로이먼트가 파드를 실행.
- 파드는 노드에서 실행되고, 필요하면 확장하거나 재시작.
- 자주 나오는 질문
- 쿠버네티스와 도커의 차이:
도커는 컨테이너를 만드는 도구이고, 쿠버네티스는 여러 컨테이너를 관리하는 도구이다. - 파드(Pod):
쿠버네티스에서 관리되는 가장 작은 단위이며, 컨테이너가 실행되는 환경이다. - 디플로이먼트:
쿠버네티스에서 애플리케이션의 배포와 업데이트를 관리하는 역할을 한다. - 노드(Node):
컨테이너가 실행되는 물리적/가상 서버를 의미한다. - 클러스터:
여러 노드가 모여 하나의 시스템처럼 작동하는 구조이다.
- 쿠버네티스와 도커의 차이:
- 실제 면접 팁
- 모르는 질문에 당황하지 않고 기본 개념을 활용해 설명한다.
예: “파드가 문제를 일으키면?” → “파드는 쿠버네티스가 자동으로 재시작하거나 복구한다.” - 학습 흔적을 어필한다.
예: “쿠버네티스 클러스터를 직접 구성해 보지는 않았지만, 클러스터의 역할과 작동 원리를 이해하고 있다.” - 자신 있게 대답한다.
예: “컨테이너 기반 애플리케이션 관리를 효율화한다는 점에서 중요하다고 생각한다.”
- 모르는 질문에 당황하지 않고 기본 개념을 활용해 설명한다.
이 정도로 간단히 정리하면 면접에서 충분히 어필할 수 있다.
추가
💡 최근에 읽은 기술 관련 책 이름이 무엇이고 인상 깊었던 부분을 얘기해주세요.
💡 본인이 사용했던 기술들과 그 기술을 사용했던 이유에 대해 설명하고, 대체 기술도 알고 있다면 얘기해주세요.
💡 하나의 비지니스 로직을 작성할 때 어느 수준으로 작성하는지, 무엇을 중요하게 생각하는지 얘기해주세요
💡 신규 기술을 도입해본 사례가 있으면 얘기해주세요.
💡 초당 100만개 씩 들어오는 요청에 대해 10000번째로 들어온 요청의 사용자를 어떻게 찾을 것인지 설명해주세요.
💡 프로젝트를 진행하면서 어려웠던 점이 있었다면 설명해주세요.
💡 앞으로 쌓거나 경험하고 싶은 개발자 커리어가 있다면 얘기해주세요.
참조
TODO
-
빌드과정
-
부팅과정
-
쿠키 vs 로컬스토리지
-
버퍼란
-
네트워크 패킷 출력까지의 경로
-
OAuth
-
TDD(Test-Driven-Development)
-
DDD(Domain-Driven-Design)
-
MSA(Microservice Architecture)
-
쿠버네티스
-
spring ci/cd