 GoByeonghu's Blog
GoByeonghu's Blog
Java Intro
자바 기초 학습하기
본 문서는 다른 언어를 통해 언어, 객체지향에 대한 기본 개념이 있는 개발자가 JAVA를 빠르게 이해하기 위한 문서입니다.
Java는 제임스 고슬링(James Gosling)이 개발하였다. 1995년 Sun Microsystems에서 처음 발표되었으며, 현재는 Oracle에서 관리하고 있다.
Java는 엄격한 객체지향 프로그래밍 언어이다. 소프트웨어의 모듈성, 유지보수성, 재사용성을 증가시켜 대규모 소프트웨어 개발에 매우 적합하다.
Java의 구조
JVM (Java Virtual Machine)
Java는 “한 번 작성하면 어디서나 실행 가능(Write Once, Run Anywhere, WORA)”이라는 철학을 가지고 있다. 자바로 작성된 프로그램은 JVM 덕분에 어떠한 하드웨어나 플랫폼에서도 동일한 결과물을 실행할 수 있다.
JDK와 JRE
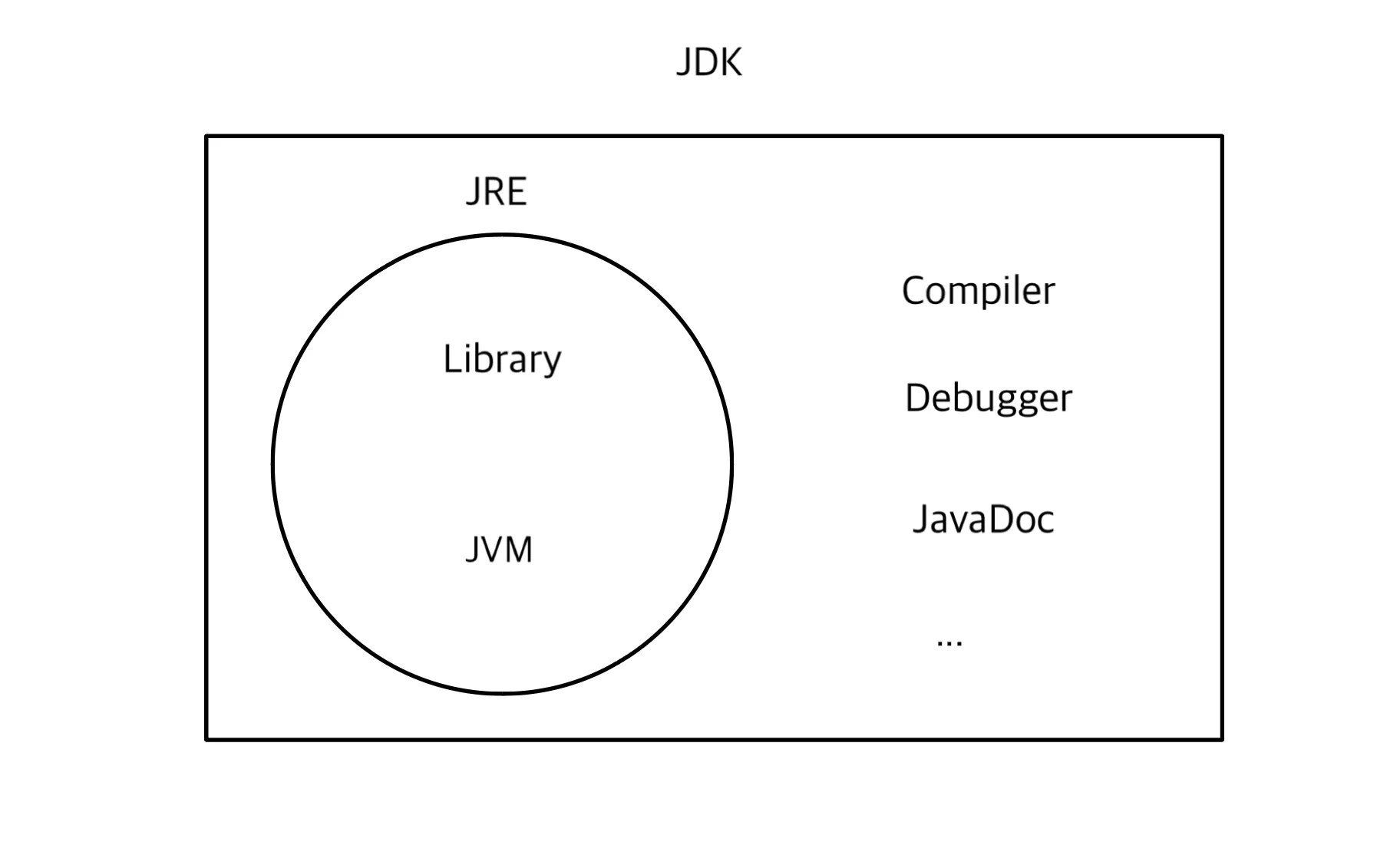
JDK (Java Development Kit)
JDK는 Java 애플리케이션 개발 및 실행을 위해 필요한 도구를 포함한 소프트웨어 환경이다.
JRE (Java Runtime Environment)
JRE는 Java 애플리케이션 실행 환경이다. JDK에 포함되어 있으며, 독립적으로 설치할 수도 있다. 개발 과정에서는 JDK를 설치하고, 배포 환경에서는 JRE만 설치하여 실행 환경을 구성할 수 있다.
Java의 컴파일 및 런타임
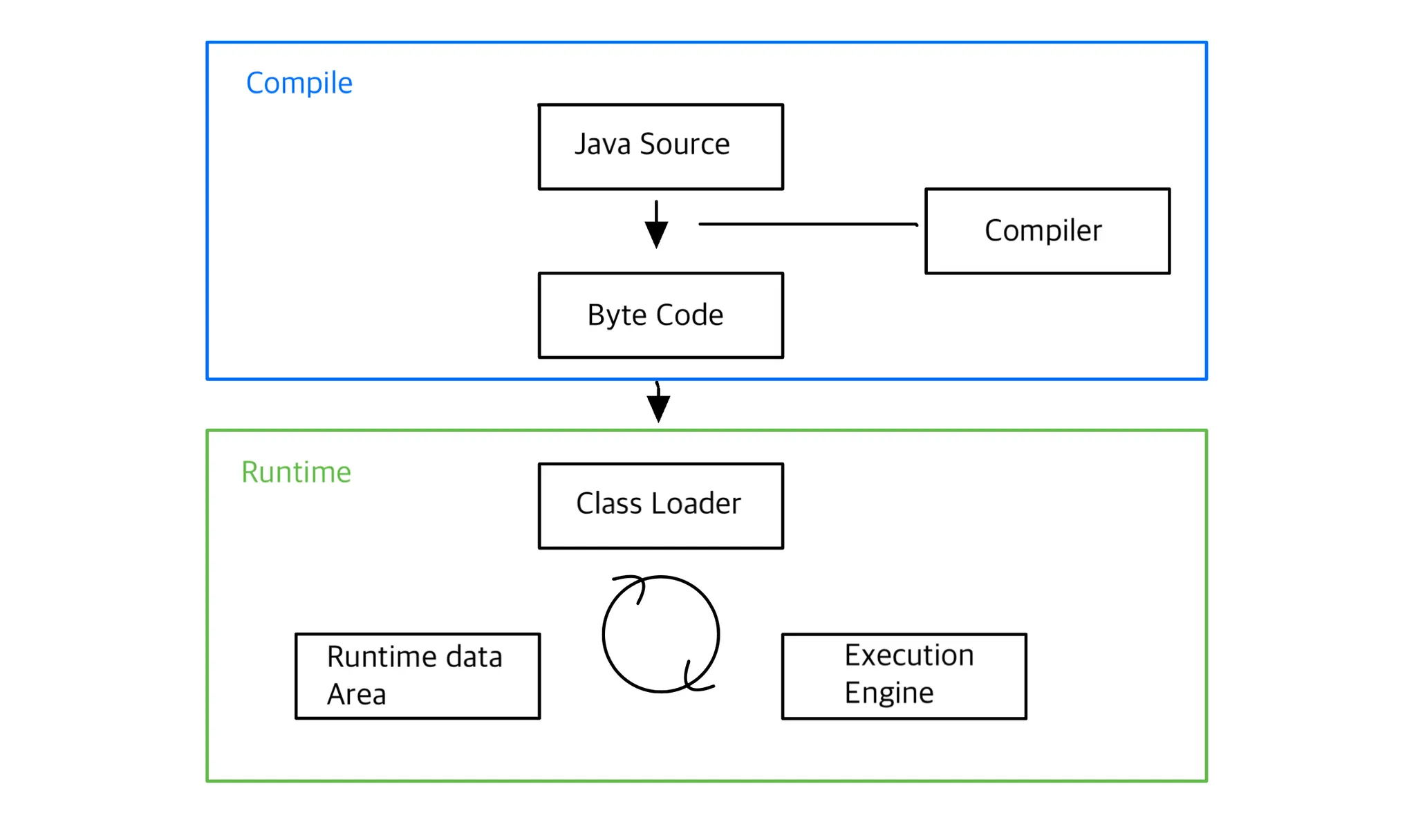
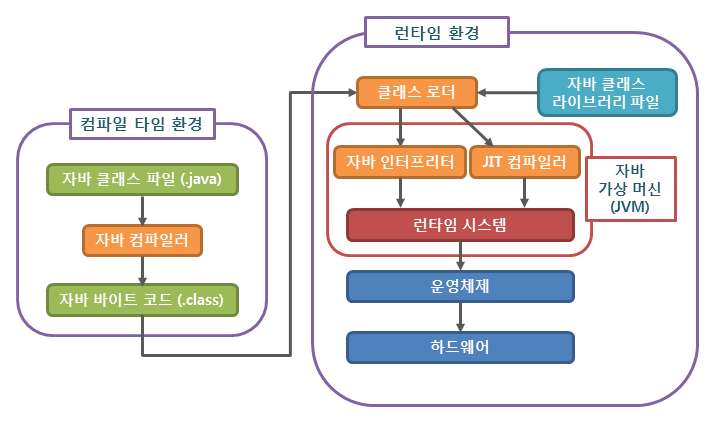
컴파일(Compile)
컴파일은 javac 컴파일러를 사용하여 Java 소스 코드(.java)를 바이트 코드(.class)로 변환하는 과정이다. 이 과정에서 코드의 정적 점검이 이루어진다.
런타임(Runtime)
런타임은 컴파일된 바이트 코드를 JVM이 실행하는 과정이다. 이 과정에서 바이트 코드는 기계어로 변환되고, JVM의 메모리 영역에서 실행된다.
JVM (Java Virtual Machine)
JVM은 Java 애플리케이션 실행을 담당하는 가상 머신이다. 아래의 3가지 핵심 구성 요소로 이루어져 있다.
Class Loader
클래스 로더는 .class 파일을 메모리에 로드하고 실행 준비를 한다. 주요 단계는 다음과 같다:
- 로딩: 바이트 코드를 메모리에 적재한다.
- 링크: 코드 검증, 메모리 준비, 메모리 주소 변환을 수행한다.
- 초기화: 정적 변수와 코드 블록을 실행한다.
Runtime Data Area
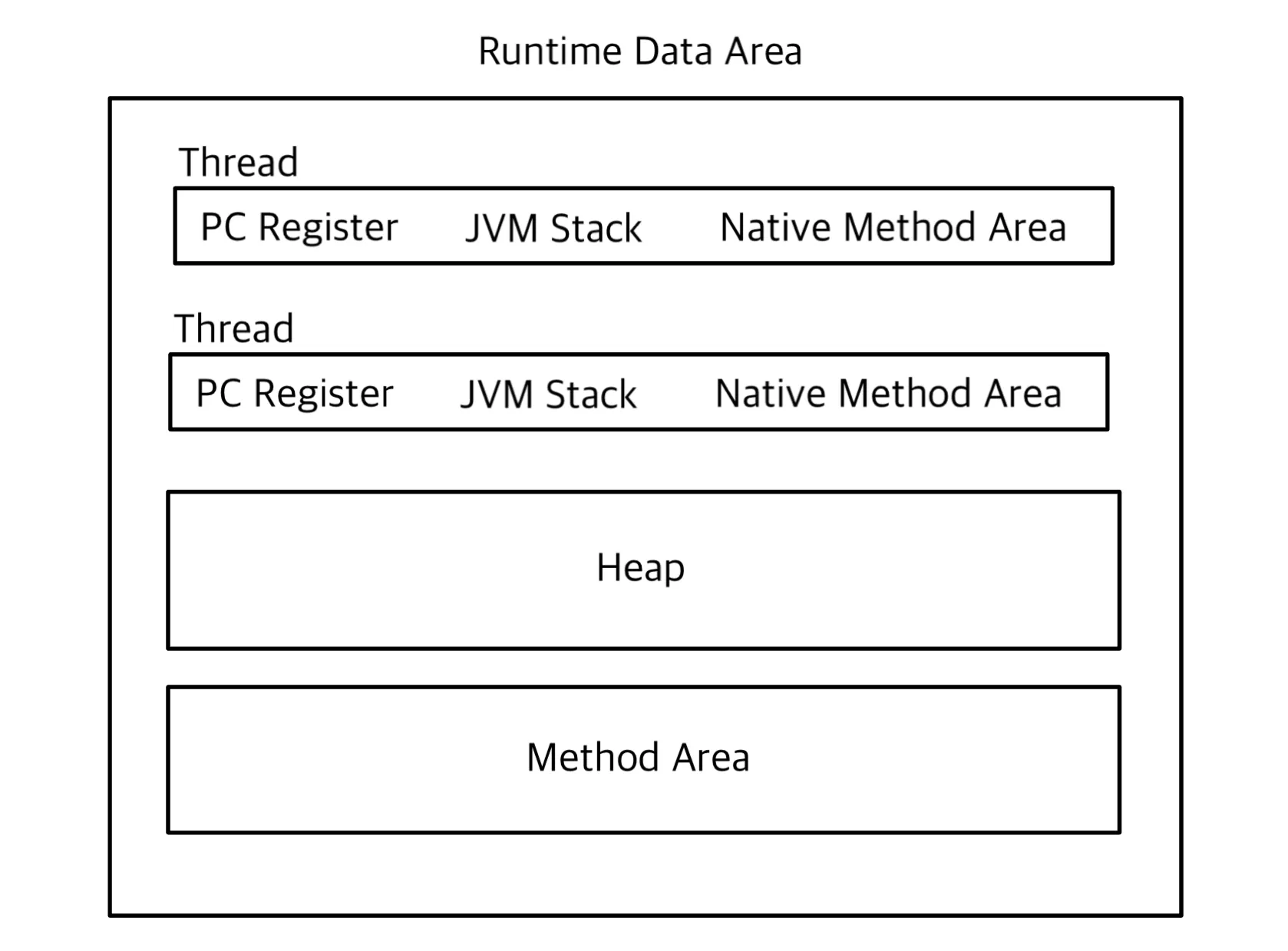
Runtime Data Area는 JVM이 프로그램 실행 중 사용하는 메모리 영역이다.
- PC Register: 현재 실행 중인 명령을 관리한다.
- JVM Stack: 지역 변수와 메서드 실행 데이터를 저장한다.
- Native Method Area: 네이티브 코드(C, C++) 실행을 위한 영역이다.
- Heap: 객체와 배열을 저장하며, GC(가비지 컬렉터)가 메모리를 관리한다.
- Method Area: 클래스 정보와 정적 데이터를 저장한다.
Execution Engine
실행 엔진은 바이트 코드를 기계어로 변환하고 실행한다.
- 인터프리터: 바이트 코드를 한 줄씩 변환하여 실행하지만 반복 코드에서 비효율적이다.
- JIT 컴파일러: 반복 실행되는 코드를 미리 기계어로 컴파일하여 속도를 향상한다.
- 가비지 컬렉터(GC): 더 이상 참조되지 않는 객체를 제거하여 메모리를 관리한다.
런타임 동작 과정
자바의 ClassLoader가 메모리로 가지고 온 바이트코드는 Runtime Data Area의 Method Area에 위치한다. 이후 이 바이트코드는 Execution Engine을 통해 실행 가능한 네이티브 코드로 변환된다.
ClassLoader는 바이트코드를 Method Area에 로드하고, 이 바이트코드는 이후 Execution Engine을 통해 네이티브 코드로 변환되어 CPU에서 실행된다.
- ClassLoader:
- 자바의
ClassLoader는 클래스 파일(.class)을 JVM 메모리로 로드한다. - 로드된 바이트코드는
Method Area에 저장된다. 이곳은 JVM의 실행 중인 프로그램에 의해 사용하는 클래스, 메소드 등의 메타데이터와 바이트코드를 저장하는 공간이다.
- 자바의
- Method Area:
Method Area는 클래스의 바이트코드, 상수 풀, 메소드 및 필드 정보 등을 보유한다.- 이 공간에 로드된 바이트코드는 아직 실행되지 않은 상태이며, 자바의 클래스 파일을 메모리에 로드하는 역할을 한다.
- Execution Engine:
- JVM의 Execution Engine은 바이트코드를 실제 CPU가 실행할 수 있는 네이티브 코드로 변환한다.
- 이 변환은 Just-In-Time (JIT) 컴파일러를 사용하거나 인터프리터 방식을 통해 이루어진다.
- 인터프리터는 바이트코드를 한 줄씩 읽어 실행한다.
- JIT 컴파일러는 자주 실행되는 바이트코드를 네이티브 코드로 미리 변환하여 실행 속도를 최적화한다.
- Native Code:
- JIT 컴파일러가 최적화된 네이티브 코드를 생성하며, 이 코드는 CPU에서 직접 실행될 수 있다.
클래스 로딩과 메모리 할당
인스턴스화된 변수는 Runtime Data Area의 Heap 영역에 위치한다. 이 과정에 대해 좀 더 구체적으로 설명하자면:
- 인스턴스 변수는 Heap 영역에 위치하며, 객체가 생성될 때 할당된다.
- 참조 변수는 Stack에 저장되며, 객체를 가리키는 역할을 한다.
1. 클래스 로딩과 메모리 할당
- 자바 클래스가 로드될 때, Method Area에 클래스에 대한 메타데이터와 바이트코드가 저장된다.
- 인스턴스화된 변수(객체의 필드)는 객체를 생성할 때 Heap 메모리 영역에 할당된다.
2. Heap 영역
- Heap은 자바에서 동적으로 할당되는 객체와 그 객체의 인스턴스 변수가 위치하는 곳이다.
- 객체가
new키워드를 통해 인스턴스화되면, 해당 객체는 Heap에 생성된다. - 객체가 생성될 때 그 객체의 인스턴스 변수는 Heap에 할당되며, 객체 참조 변수는 Stack에 위치하게 된다.
3. Stack 영역
- Stack은 메서드 호출과 관련된 변수들이 저장되는 곳이다. 각 메서드 호출 시, 그 메서드의 로컬 변수나 매개변수들이 Stack에 저장된다.
- Heap에 있는 객체에 대한 참조 변수는 Stack에 저장된다.
4. Lifecycle
- 객체는 Heap에 위치하면서, 메서드 호출 시
new키워드를 통해 인스턴스화된 후 사용된다. - 객체의 인스턴스 변수는 객체의 생애주기 동안 Heap에 계속 존재하며, 가비지 컬렉션에 의해 객체가 더 이상 참조되지 않을 때 메모리에서 해제된다.
스레드에서 생성된 인스턴스는 어디에 위치하는가
스레드에서 생성된 인스턴스는 스레드의 Stack에 저장되지 않는다. 대신, 객체의 인스턴스는 여전히 Heap 영역에 저장된다. 다만, 스레드마다 고유한 Stack 영역이 존재하므로, 각 스레드는 자신만의 로컬 변수와 메서드 호출 정보를 Stack에 저장하게 된다.
- Heap 영역:
- 객체가
new로 생성될 때, 객체의 인스턴스 변수와 데이터는 Heap에 저장된다. - Heap 영역은 JVM 전체에서 공유되며, 여러 스레드가 동일한 객체를 참조할 수 있다.
- 객체가
- Stack 영역:
- 각 스레드는 자신만의 Stack을 가진다. 이 Stack에는 해당 스레드가 호출한 메서드들의 로컬 변수와 매개변수가 저장된다.
- 로컬 변수는 기본 데이터 타입(예:
int,float)과 객체 참조 변수가 포함된다. - 객체의 참조 변수는 Stack에 저장되며, 이는 Heap에 저장된 객체를 가리킨다.
- 즉, Stack에 저장된 변수는 객체의 실제 데이터가 아닌 객체의 참조만 담고 있다.
스레드와 인스턴스:
- 스레드에서 생성된 인스턴스는 Heap에 위치하지만, 해당 인스턴스를 참조하는 참조 변수는 각 스레드의 Stack에 저장된다.
- 만약 여러 스레드가 동일한 객체를 참조한다면, 그 객체는 Heap에서 공유되며, 각 스레드의 Stack은 객체를 참조하는 변수만을 가지게 된다.
결론:
- 객체의 인스턴스는 Heap에 저장되고, 참조 변수는 Stack에 저장된다.
- 스레드는 서로 다른 Stack을 가지지만, Heap에 있는 동일한 객체를 참조할 수 있다.
Java의 기초 사용법
기본 자료형 (Primitive Data Types)
| 타입 | 바이트 크기 | 값의 범위 | 설명 |
|---|---|---|---|
byte |
1 | -128 to 127 | 매우 작은 정수 저장용. 네트워크 데이터 처리에 유용 |
short |
2 | -32,768 to 32,767 | 작은 정수 저장용. byte보다 큰 범위 제공 |
int |
4 | -2,147,483,648 to 2,147,483,647 | 일반적으로 사용되는 정수 저장용. 가장 자주 사용됨 |
long |
8 | -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 | 매우 큰 정수 저장용 |
float |
4 | ±3.40282347E+38F | 실수 저장용. 부동소수점 연산에 사용 |
double |
8 | ±1.79769313486231570E+308 | 더 큰 실수 저장용. 정밀한 부동소수점 연산에 사용 |
char |
2 | ‘\u0000’ to ‘\uffff’ (0 to 65,535) | 단일 문자 저장용. 유니코드 문자 표현 가능 |
boolean |
1 bit | true, false |
논리값 저장용. 조건문과 제어문에 주로 사용 |
public class PrimitiveExamples {
public static void main(String[] args) {
byte myByte = 100;
short myShort = 5000;
int myInt = 100000;
long myLong = 15000000000L;
float myFloat = 5.75f;
double myDouble = 19.99;
char myChar = 'A';
boolean myBoolean = true;
System.out.println("Byte: " + myByte);
System.out.println("Short: " + myShort);
System.out.println("Int: " + myInt);
System.out.println("Long: " + myLong);
System.out.println("Float: " + myFloat);
System.out.println("Double: " + myDouble);
System.out.println("Char: " + myChar);
System.out.println("Boolean: " + myBoolean);
}
}
참조 자료형 (Reference Data Types)
참조 자료형은 클래스, 배열, 인터페이스 등을 포함하며, new 키워드를 사용하여 객체를 생성한다.
public class SomeClass {
String text;
public SomeClass(String text) {
this.text = text;
}
public void greet() {
System.out.println(this.text);
}
public static void main(String[] args) {
SomeClass object1 = new SomeClass("Hello, Java!");
object1.greet();
}
}
메서드 (Method)
메서드는 특정 작업을 수행하는 코드 블록으로, 접근제어자, 반환 타입, 메서드명, 매개 변수로 구성된다.
public class MethodExample {
// 메서드 정의
public static int add(int a, int b) {
return a + b;
}
public static void main(String[] args) {
int result = add(3, 7);
System.out.println("Sum: " + result);
}
}
접근 제어자 (Access Modifiers)
자바에서 사용되는 접근 제어자(Access Modifiers)는 클래스, 메서드, 변수 등의 접근 범위를 제한하는 키워드이다. 이를 통해 코드의 캡슐화를 실현하고, 의도하지 않은 접근을 방지할 수 있다.
접근 제어자의 종류와 특징
| 접근 제어자 | 클래스 내 | 패키지 내 | 하위 클래스 | 전역 |
|---|---|---|---|---|
public |
O | O | O | O |
protected |
O | O | O | X |
default |
O | O | X | X |
private |
O | X | X | X |
1. public
- 모든 클래스에서 접근 가능하다.
- 가장 높은 접근 수준을 제공한다.
- 외부 패키지 및 클래스에서도 자유롭게 사용할 수 있다.
public class PublicExample {
public int value = 10;
public void displayValue() {
System.out.println("Value: " + value);
}
}
2. protected
- 같은 패키지 내의 클래스 또는 다른 패키지의 하위 클래스에서 접근 가능하다.
- 외부 클래스에서는 접근이 제한된다.
public class Parent {
protected String name = "Parent";
protected void greet() {
System.out.println("Hello from " + name);
}
}
class Child extends Parent {
public void display() {
greet(); // 부모 클래스의 protected 메서드 접근 가능
}
}
3. default (접근 제어자를 명시하지 않음)
- 같은 패키지 내에서만 접근 가능하다.
- 패키지-프라이빗 접근 수준이라고도 한다.
- 접근 제어자를 명시하지 않으면 기본적으로 default 접근 수준이 설정된다.
class DefaultExample {
int number = 42; // default 접근 제어자
void showNumber() {
System.out.println("Number: " + number);
}
}
4. private
- 선언된 클래스 내부에서만 접근 가능하다.
- 가장 제한적인 접근 수준을 제공하며, 외부에서는 접근할 수 없다.
public class PrivateExample {
private int secret = 99;
private void showSecret() {
System.out.println("Secret: " + secret);
}
public void revealSecret() {
showSecret(); // 클래스 내부에서는 접근 가능
}
}
컬렉션 (Java Collections Framework, JCF)
자바 컬렉션 프레임워크(Java Collections Framework, JCF)는 데이터 구조를 효율적으로 다룰 수 있도록 자바에서 제공하는 클래스와 인터페이스의 집합이다. 이를 활용하면 데이터 저장, 검색, 수정, 삭제 등의 작업을 간편하게 수행할 수 있다.
종류
1. Collection 인터페이스
Collection은 모든 컬렉션의 기본 인터페이스로, 요소 추가, 제거, 탐색 등의 메서드를 제공한다.
2. Set 인터페이스
- 중복을 허용하지 않는 컬렉션이다.
- 요소들의 순서를 보장하지 않는다.
- 주요 구현 클래스:
HashSet: 해시 테이블을 기반으로 하며, 순서를 보장하지 않는다.LinkedHashSet: 입력된 순서를 유지한다.TreeSet: 정렬된 순서로 저장한다.
3. List 인터페이스
- 순서가 있는 컬렉션으로, 중복 요소를 허용한다.
- 요소를 인덱스를 통해 접근할 수 있다.
- 주요 구현 클래스:
ArrayList: 동적 배열로 구현되어 있다.LinkedList: 연결 리스트로 구현되어 있다.Vector: 동기화를 지원하며, 스택과 유사하다.Stack: LIFO(Last In, First Out) 구조를 제공한다.
4. Queue 인터페이스
- FIFO(First In, First Out) 구조를 가지는 컬렉션이다.
- 주요 구현 클래스:
LinkedList: 연결 리스트 기반의 큐 구현체이다.PriorityQueue: 우선순위에 따라 요소를 관리한다.
5. Map 인터페이스
- 키와 값의 쌍으로 이루어진 데이터를 저장하는 컬렉션이다.
- 키는 중복을 허용하지 않으며, 값은 중복을 허용한다.
- 주요 구현 클래스:
HashMap: 해시 테이블 기반으로 데이터를 저장한다.LinkedHashMap: 입력된 순서를 유지한다.TreeMap: 키를 정렬된 순서로 저장한다.Hashtable: 동기화를 지원한다.
컬렉션 구조 다이어그램
JCF 관점 전체 컬렉션 구조") List("List
순서가 있는 자료 접근") Set("Set
중복없이 자료 접근") Map("Map
키와 값으로 데이터 접근") LinkedList("LinkedList
연결리스트로 구현된 리스트") Stack("Stack
스택구조로 접근") Vector("Vector
동기화 지원") ArrayList("ArrayList
동적 배열로 접근") HashSet("HashSet
동적 해시 테이블로 구현") SortedSet("SortedSet
정렬된 자료 접근 가능한 인터페이스") TreeSet("TreeSet
트리 구조로 정렬된 자료 접근") Hashtable("Hashtable
동기화 지원하는 Map 자료구조") HashMap("HashMap
동적 해시맵으로 데이터 접근") SortedMap("SortedMap
정렬된 자료로 Map 자료 접근") TreeMap("TreeMap
트리 구조로 정렬된 Map 자료 접근") Collection --> List Collection --> Set Collection --> Map List --> LinkedList List --> Stack List --> Vector List --> ArrayList Set --> HashSet Set --> SortedSet SortedSet --> TreeSet Map --> Hashtable Map --> HashMap Map --> SortedMap SortedMap --> TreeMap
Collection의 상속 구조
Java Collections Framework의 클래스와 인터페이스는 상속 관계를 통해 구조화되어 있다.
1. 기본 상속 구조
Collection은 모든 컬렉션 클래스의 상위 인터페이스이다.List와 Set은 각각 순서와 중복 여부를 기준으로 구현된다.
JCF 관점 전체 컬렉션 구조") List("List
순서가 있는 자료 접근") Set("Set
중복없이 자료 접근") LinkedList("LinkedList
연결리스트로 구현된 리스트") Stack("Stack
스택구조로 접근") Vector("Vector
동기화 지원") ArrayList("ArrayList
동적 배열로 접근") HashSet("HashSet
동적 해시 테이블로 구현") SortedSet("SortedSet
정렬된 자료 접근 가능한 인터페이스") TreeSet("TreeSet
트리 구조로 정렬된 자료 접근") Collection --> List Collection --> Set List --> LinkedList List --> Stack List --> Vector List --> ArrayList Set --> HashSet Set --> SortedSet SortedSet --> TreeSet
2. Map 구조
Map은 Collection과 별도로 키-값 쌍 구조를 제공한다. 구현 클래스는 다양한 정렬 및 동기화 방식에 따라 분리된다.
키와 값으로 데이터 접근") Hashtable("Hashtable
동기화 지원하는 Map 자료구조") HashMap("HashMap
동적 해시맵으로 데이터 접근") SortedMap("SortedMap
정렬된 자료로 Map 자료 접근") TreeMap("TreeMap
트리 구조로 정렬된 Map 자료 접근") Map --> Hashtable Map --> HashMap Map --> SortedMap SortedMap --> TreeMap
참고
- Java Collections Framework 공식 문서: Oracle Java Documentation
- Wikipedia: Java Collections Framework
Interface
인터페이스는 자바에서 클래스가 구현해야 하는 메서드의 형태를 정의하는 추상적인 형식이다. 인터페이스를 사용하면 객체가 구현해야 할 메서드의 규약을 정할 수 있다. 또한, 다중 상속을 지원하지 않는 자바에서 인터페이스는 여러 클래스에서 상속받을 수 있어 유용하다.
사용방법
인터페이스는 다음과 같은 형식으로 정의한다.
[visibility] interface InterfaceName [extends other interfaces] {
constant declarations (default is abstract)
method declarations static method declarations
}
//(ex)
public interface InterfaceName extends OtherInterfaces {
int someIntValue;
abstract void someMethod();
static void someStaticMethod();
};
예시 코드:
- 기본 인터페이스
- 인터페이스는
abstract메서드를 선언한다. 메서드 구현은 인터페이스를 구현한 클래스에서 해야 한다.
- 인터페이스는
public interface Vehicle { int MAX_SPEED = 120; // 상수 선언
void start(); // 추상 메서드 선언
void stop();
}
Vehicle인터페이스는 두 개의 추상 메서드start()와stop()을 선언한다.MAX_SPEED는 상수로 정의되어 있다.
- 인터페이스 상속
- 인터페이스는 다른 인터페이스를 상속받을 수 있다. 이렇게 상속받은 인터페이스는 부모 인터페이스의 메서드를 모두 구현해야 한다.
public interface ElectricVehicle extends Vehicle {
void chargeBattery(); // 추가 추상 메서드 선언
}
ElectricVehicle인터페이스는Vehicle인터페이스를 상속하고,chargeBattery()라는 새로운 메서드를 추가한다.
- 정적 메서드 포함
- 인터페이스는
static메서드를 선언할 수 있다.static메서드는 인터페이스의 인스턴스를 생성하지 않고도 호출할 수 있다.
- 인터페이스는
public interface Gadget {
int WARRANTY_PERIOD = 1; // 상수 선언
void turnOn(); // 추상 메서드 선언
void turnOff();
static void resetSettings() { // 정적 메서드 선언
System.out.println("설정을 초기화합니다.");
}
}
Gadget인터페이스는turnOn()과turnOff()라는 추상 메서드 외에도resetSettings()라는 정적 메서드를 선언한다. 이 메서드는 인터페이스 이름으로 직접 호출할 수 있다.
Gadget.resetSettings(); // 정적 메서드 호출
Math
C++에서 수학 함수를 제공하는 <cmath> 헤더와 유사한 역할을 Java에서 수행하는 클래스는 java.lang.Math이다.
Java에서는 기본적으로 Math 클래스에 다양한 수학 함수들이 포함되어 있고, 이는 static 메서드로 제공된다.
추가적으로, 고급 수학 함수는 StrictMath, BigDecimal, BigInteger 등에서도 제공한다.
import java.lang.Math; // 생략 가능 (java.lang 패키지는 자동 import)
주요 기능 비교 (C++ vs Java)
| 기능 | C++ <cmath> 함수 |
Java Math 메서드 |
|---|---|---|
| 절댓값 | abs(x) |
Math.abs(x) |
| 제곱근 | sqrt(x) |
Math.sqrt(x) |
| 거듭제곱 | pow(x, y) |
Math.pow(x, y) |
| 삼각함수 | sin(x), cos(x) |
Math.sin(x), Math.cos(x) |
| 로그 | log(x) (자연로그) |
Math.log(x) |
| 상용로그 | log10(x) |
Math.log10(x) |
| 지수 함수 | exp(x) |
Math.exp(x) |
| 반올림/내림/올림 | round, floor, ceil |
Math.round, Math.floor, Math.ceil |
| 최소/최대 | min(x,y), max(x,y) |
Math.min(x, y), Math.max(x, y) |
| 나머지 | fmod(x, y) |
Math.IEEEremainder(x, y) 또는 % |
| 삼각역함수 | asin, acos, atan |
Math.asin, Math.acos, Math.atan |
| 하이퍼볼릭 함수 | sinh, cosh, tanh |
Math.sinh, Math.cosh, Math.tanh |
| π, e 상수 | M_PI, M_E 등 |
Math.PI, Math.E |
사용 예시
public class Main {
public static void main(String[] args) {
double x = -3.14;
double y = 2.0;
System.out.println("abs: " + Math.abs(x)); // 3.14
System.out.println("sqrt: " + Math.sqrt(16)); // 4.0
System.out.println("pow: " + Math.pow(2, 3)); // 8.0
System.out.println("sin: " + Math.sin(Math.PI / 2)); // 1.0
System.out.println("log: " + Math.log(Math.E)); // 1.0
System.out.println("ceil: " + Math.ceil(x)); // -3.0
System.out.println("floor: " + Math.floor(x)); // -4.0
System.out.println("round: " + Math.round(x)); // -3
}
}
고정 소수점 계산이 필요할 경우
Java는 float, double이 정확하지 않기 때문에, 정밀한 계산이 필요한 경우 BigDecimal을 사용한다.
import java.math.BigDecimal;
BigDecimal a = new BigDecimal("1.1");
BigDecimal b = new BigDecimal("2.2");
BigDecimal result = a.add(b);
System.out.println(result); // 3.3
요약
| 항목 | Java에서 사용하는 클래스 |
|---|---|
| 기본 수학 함수 | java.lang.Math |
| 고정 소수점 | java.math.BigDecimal |
| 큰 정수 계산 | java.math.BigInteger |
| 더 정확한 계산 (완전 재현용) | StrictMath |
Thread
Thread는 Runnable의 구현체이다. 스레드는 자바 프로그램에서 병렬 실행을 가능하게 해주는 중요한 기능이다.
예시 코드
public class MainSimpleCase1Thread {
public static void main(String[] args) {
Thread thread = new Thread();
thread.start(); // 새 스레드를 시작
}
}
위 코드는 Thread 객체를 생성하고 start() 메서드를 호출하여 새로운 스레드를 시작한다.
레이스 컨디션 해결 방법 (동시성 문제와 레이스 컨디션 차이)
Race Condition은 여러 스레드가 동시에 실행될 때 예상치 못한 결과를 초래하는 문제이다. 이를 해결하기 위한 방법은 다음과 같다.
- synchronized (mutex):
synchronized는 여러 스레드가 공유 자원에 접근할 때, 하나의 스레드만 접근할 수 있도록 보장하는 메커니즘이다. 이를 통해 동시성 문제를 해결할 수 있다.- 메서드 동기화 스타일:
synchronized키워드를 메서드 선언에 사용하여, 해당 메서드에 대해 동기화를 적용할 수 있다. - 블록 동기화 스타일: 코드 블록을
synchronized로 감싸서 특정 코드 부분에만 동기화를 적용할 수 있다.
주의: 동기화에서 중요한 문제는 데드락(Deadlock)이다. 데드락은 여러 스레드가 서로가 점유한 자원을 기다리는 상태를 의미한다.
- volatile:
volatile키워드는 변수의 값을 스레드마다 독립적으로 저장하지 않고, 항상 메인 메모리에서 읽어온다. 이를 통해 메모리 가시성 문제를 해결할 수 있다.- 중요:
volatile은 변수의 원자성을 보장하지 않는다. 원자성 문제는atomic,lock,mutex등의 메커니즘을 통해 해결할 수 있다.
Semaphore (세마포어)
세마포어는 다수의 스레드가 공유 자원에 접근할 때, 자원의 수를 제한하여 동시성 문제를 해결하는 방법이다.
사용 방법
자바에서 세마포어는 java.util.concurrent 패키지에 포함되어 있으며, Semaphore 클래스를 사용하여 구현할 수 있다. Semaphore 클래스는 두 가지 주요 메서드인 acquire()와 release()를 제공한다.
acquire():- 세마포어의 허용 가능한 값이 0보다 큰 경우 값을 감소시키고 자원을 획득한다.
- 값이 0이면, 자원이 반환될 때까지 대기한다.
release():- 세마포어의 값을 증가시키고, 대기 중인 스레드가 자원을 사용할 수 있도록 허용한다.
세마포어는 크게 바이너리 세마포어와 카운팅 세마포어로 나눌 수 있다.
- 바이너리 세마포어: 값이 1로만 설정되며, 주로 한 번에 하나의 스레드만 자원에 접근하도록 제한하는 데 사용된다.
- 카운팅 세마포어: 값이 여러 개로 설정될 수 있으며, 특정 개수의 스레드만 자원에 접근할 수 있도록 제한한다.
Lambda
lambda 키워드는 익명 함수(anonymous function)를 정의하는 데 사용된다. 이는 프로그래밍 언어에서 함수를 일급 객체(first-class citizen)로 취급하는 개념의 기반이다.
1. 변수에 할당할 수 있다
함수는 변수에 할당될 수 있다. 이를 통해 함수 자체를 변수처럼 사용할 수 있다.
2. 함수의 매개변수로 전달할 수 있다
함수는 다른 함수의 매개변수로 전달될 수 있다. 이를 통해 함수의 동작을 매개변수로 전달하여 더 유연한 코드 구성을 할 수 있다.
3. 함수의 반환값으로 사용할 수 있다
함수는 다른 함수의 반환값으로 사용할 수 있다. 이를 통해 함수를 생성하고 반환하는 함수, 즉 고차 함수(higher-order function)를 만들 수 있다.
Stream API
스트림 API는 람다식을 포함한 함수형 인터페이스를 이용하여 데이터 소스(컬렉션, 배열, 난수, 파일 등)를 처리하고, 데이터를 조작, 가공, 변환하여 원하는 결과를 얻을 수 있게 해주는 자바의 인터페이스이다.
자바에서 함수를 일급 객체로 다룰 때는 크게 Function API와 Stream API 두 가지가 있다. 여기서는 스트림에 대해서만 다룬다.
스트림 API를 사용하는 이유는 스트림을 통해 선언형 방식으로 컬렉션 데이터를 처리할 수 있기 때문이다. 스트림을 사용하면 반복문과 조건문을 여러 줄로 작성하지 않고도 간결하고 직관적인 코드로 작성할 수 있다. 또한, 스트림 API는 다양한 데이터 소스에 대해 일관된 작업을 수행하고, 병렬 처리를 통해 성능을 최적화할 수 있는 유연성을 제공한다.
-
선언형 처리: 스트림을 사용하면 반복문 대신 선언형으로 데이터를 처리할 수 있다.
-
체이닝: 여러 연산을 체인 형태로 연결할 수 있다.
여러 개의 함수를 이미지처럼 이어 붙여 사용할 수 있다.
- 지연 연산: 중간 연산은 지연(lazy) 연산이며, 최종 연산이 호출될 때까지 실행되지 않는다.
- 병렬 처리: 쉽게 병렬 스트림을 생성하여 병렬 처리를 수행할 수 있다.
람다 표현식 예시
/* 기본 형식 */
(parameters) -> expression
(parameters) -> { statements; }
- 매개변수가 없고 반환값도 없는 람다 표현식:
() -> System.out.println("Hello, World!"); - 하나의 매개변수를 받고, 그 매개변수를 출력하는 람다 표현식:
(x) -> System.out.println(x); - 두 개의 매개변수를 받아 그 합을 반환하는 람다 표현식:
(a, b) -> a + b; - 여러 줄의 코드가 있는 람다 표현식:
(a, b) -> { int sum = a + b; return sum; };
스트림 API 예시
import java.util.Arrays;
import java.util.List;
public class StreamExample {
public static void main(String[] args) {
// 리스트 생성
List<String> names = Arrays.asList("김철수", "이영희", "박민수", "최지우", "한예슬");
// 스트림 생성 및 중간 연산과 최종 연산 적용
List<String> filteredNames = names.stream()
.filter(name -> name.startsWith("김"))
.toList();
// 결과 출력
filteredNames.forEach(System.out::println); // 출력: 김철수
}
}
List<String>타입의names리스트를 생성한다.names.stream()을 호출하여 스트림을 생성한다.filter중간 연산을 사용하여 이름이 “김”으로 시작하는 항목만 필터링한다.collect최종 연산을 사용하여 필터링된 결과를 리스트로 수집한다.forEach를 사용하여 결과 리스트의 각 요소를 출력한다.
중간 연산과 최종 연산
- 중간 연산은 또 다른 스트림을 반환하며, 최종 연산이 호출될 때까지 실제로 수행되지 않는다. 이를 지연 평가(lazy evaluation)라고 한다.
- 최종 연산은 스트림을 소모하여 결과를 만드는 연산이다. 최종 연산이 호출되면 스트림의 요소들이 실제로 처리되며, 최종 연산 후에는 스트림을 더 이상 사용할 수 없다.
import java.util.*;
import java.util.stream.*;
public class StreamExample {
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Anna");
// 스트림을 생성하고 중간 연산과 최종 연산을 수행
List<String> result = names.stream()
.filter(name -> name.startsWith("A")) // 중간 연산: 필터링
.map(String::toUpperCase) // 중간 연산: 대문자로 변환
.sorted() // 중간 연산: 정렬
.collect(Collectors.toList()); // 최종 연산: 리스트로 수집
System.out.println(result); // 출력: [ALICE, ANNA]
}
}
스트림 API의 추상화와 파이프라인
스트림 API는 데이터를 처리하는 복잡한 로직을 추상화하여 간단하고 직관적인 방법으로 데이터를 다룰 수 있게 해준다. 데이터 소스의 세부 사항을 신경 쓰지 않고 데이터 처리 작업에 집중할 수 있다.
-
전통적인 방법
명령형 프로그래밍 스타일로, 데이터 처리의 각 단계를 명확하게 작성해야 한다.
import java.util.ArrayList; import java.util.Arrays; import java.util.List; public class TraditionalExample { public static void main(String[] args) { List<String> names = Arrays.asList("김철수", "이영희", "박민수", "최지우", "한예슬"); List<String> result = new ArrayList<>(); // 필터링 및 변환 작업 for (String name : names) { if (name.startsWith("이")) { result.add(name.toUpperCase()); } } // 결과 출력 for (String name : result) { System.out.println(name); } } } -
스트림을 사용한 방법
선언형 프로그래밍 스타일로, 데이터를 어떻게 처리할지 선언만 하면 된다.
import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class StreamExample { public static void main(String[] args) { List<String> names = Arrays.asList("김철수", "이영희", "박민수", "최지우", "한예슬"); // 스트림 파이프라인: 필터링 및 변환 작업 List<String> result = names.stream() // 스트림 생성 .filter(name -> name.startsWith("이")) // 필터링 .map(String::toUpperCase) // 변환 .collect(Collectors.toList()); // 결과 수집 // 결과 출력 result.forEach(System.out::println); // 출력: 이영희 } }
Annotation
현 시대의 자바에서 애너테이션은 Spring AOP와 함께 쓸 때 진가를 발휘한다. AOP 없이 커스텀 애너테이션을 사용한다면 복잡도가 올라가고 유지보수가 더 어려워질 수 있다.
애노테이션(Annotation)은 라틴어 “annotatio”에서 유래한 용어이다. 라틴어로 “annotatio”는 “덧붙여 놓은 주석”이라는 뜻이다. 영어의 “annotation”도 동일한 어원을 가지고 있으며, “주석을 다는 행위” 또는 “주석 자체”를 의미한다.
Java에서는 이 개념을 차용하여, 코드에 대한 메타데이터를 제공하는 특별한 형태의 문법으로 애노테이션을 도입했다. 애노테이션은 “@” 기호와 함께 사용되며, 클래스, 메서드, 변수, 매개변수 등에 대한 부가 정보를 제공한다.
@Override
public String toString() {
// ...
}
여기서 @Override는 해당 메서드가 상위 클래스의 메서드를 오버라이드하고 있음을 나타내는 애노테이션이다. 이렇게 애노테이션을 통해 코드에 대한 메타데이터를 작성하고, 이를 컴파일러나 런타임에서 활용할 수 있게 된다.
자바에서는 다양한 내장 애노테이션이 제공되며, 사용자 정의 애노테이션도 만들 수 있다.
자바 내장 애노테이션
자바는 몇 가지 기본 애노테이션을 내장하고 있습니다. 이들은 주로 코드의 동작이나 의미를 명확히 하기 위해 사용된다.
- @Override
- 메서드가 수퍼클래스의 메서드를 오버라이드하고 있음을 나타낸다.
public class SuperClass { public void display() { System.out.println("SuperClass Method display()!"); } } public class SubClass extends SuperClass { @Override public void display() { System.out.println("SubClass display()!"); } } - @Deprecated
- 특정 요소(클래스, 메서드 등)가 더 이상 사용되지 않음을 나타내며, 다른 대안이 있음을 알린다.
- 이 애노테이션은 오픈소스 혹은 사내 자체 라이브러리가 있을 때 사용될 수 있으나, 그렇지 않으면 사용될 일이 적다.
public class Example { @Deprecated public void oldMethod() { System.out.println("This method is deprecated"); } public void newMethod() { System.out.println("This method is the replacement"); } }
커스텀 애노테이션
사용 이유
- 메타데이터 제공: 런타임이나 컴파일 타임에 필요한 정보를 제공하여 동적으로 동작을 제어할 수 있다.
예시
MyCustomAnnotation.java
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.ElementType;
import java.lang.annotation.Target;
// 이 어노테이션은 런타임에도 유지됩니다.
// 이는 JVM이 런타임에 어노테이션을 읽을 수 있음을 의미합니다.
// 이를 통해 런타임에 어노테이션 정보를 처리하는 코드를 작성할 수 있습니다.
@Retention(RetentionPolicy.RUNTIME)
// 이 어노테이션은 메소드에만 적용될 수 있습니다.
// 이는 MeasureTime 어노테이션을 메소드 선언부에만 붙일 수 있음을 의미합니다.
@Target(ElementType.METHOD)
public @interface MyCustomAnnotation {
String value() default "기본 값";
int number() default 0;
}
AnnotationProcessor.java
import java.lang.reflect.Method;
public class AnnotationProcessor {
public void processAnnotations(Object obj) {
try {
Method[] methods = obj.getClass().getDeclaredMethods();
for (Method method : methods) {
if (method.isAnnotationPresent(MyCustomAnnotation.class)) {
MyCustomAnnotation annotation = method.getAnnotation(MyCustomAnnotation.class);
System.out.println("메서드 이름: " + method.getName());
System.out.println("value: " + annotation.value());
System.out.println("number: " + annotation.number());
method.invoke(obj);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
MyClass.java
public class MyClass {
@MyCustomAnnotation(value = "테스트", number = 10)
public void myMethod() {
System.out.println("myMethod가 실행되었습니다.");
}
}
Main.java
public class Main {
public static void main(String[] args) {
MyClass myClassInstance = new MyClass();
AnnotationProcessor processor = new AnnotationProcessor();
processor.processAnnotations(myClassInstance);
}
}
아쉬운 점
new MyClass().myMethod()를 호출했을 때 함수가 실행되기 전에 @MyCustomAnnotation이 자동으로 호출되기를 기대할 수도 있다. (파이썬처럼)
하지만 자바는 기본적으로 이러한 동작 방식을 지원하지 않는다. 특정 메서드 머리에 달려 있는 애너테이션이 자동으로 실행되게 하려면 Spring의 AOP 기능을 사용해야 한다.
리플렉션(Reflection)
: 런타임 시점에 클래스나 객체의 메타데이터(클래스의 구조, 메서드, 필드 등)를 동적으로 접근하고 조작할 수 있는 기능이다. 리플렉션(Reflection)은 자바에서 실행 시간에 클래스, 메서드, 필드, 인터페이스 등을 동적으로 검사하고 조작할 수 있는 기능이다. 이를 통해 코드가 실행되는 동안에도 클래스의 구조나 상태를 분석하고 수정할 수 있다.
사용 이유
| 사용 이유 | 설명 |
|---|---|
| 동적 동작 | 실행 시점에 클래스나 객체의 정보를 얻고, 이를 바탕으로 동적으로 동작을 결정할 수 있습니다. |
| 프레임워크 및 라이브러리 개발 | 다양한 타입의 객체를 동적으로 생성하고 처리해야 하는 프레임워크나 라이브러리에서 자주 사용됩니다. |
| 디버깅 및 테스트 | 클래스의 내부 구조를 검사하여 디버깅이나 테스트를 더 효과적으로 수행할 수 있습니다. |
| 접근 제한 무시 | private, protected 등 접근 제한자를 무시하고 필드나 메서드에 접근할 수 있습니다. |
사용 방법
1. 클래스 정보 얻기
클래스 정보를 얻기 위해 Class 객체를 사용합니다.
public class ReflectionExample {
public static void main(String[] args) {
try {
// 클래스 객체를 가져오는 방법 1: Class.forName()
Class<?> clazz = Class.forName("com.example.MyClass");
// 클래스 객체를 가져오는 방법 2: 클래스명.class
Class<?> clazz2 = MyClass.class;
// 클래스 객체를 가져오는 방법 3: 객체의 getClass() 메서드 사용
MyClass myClassInstance = new MyClass();
Class<?> clazz3 = myClassInstance.getClass();
System.out.println("Class name: " + clazz.getName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
2. 필드 접근
리플렉션을 사용하여 클래스의 필드에 접근하고 값을 설정할 수 있습니다.
import java.lang.reflect.Field;
public class ReflectionExample {
public static void main(String[] args) {
try {
MyClass myClassInstance = new MyClass();
// 클래스 객체를 가져옴
Class<?> clazz = myClassInstance.getClass();
// 필드를 가져옴
Field field = clazz.getDeclaredField("privateField");
// 접근 가능하도록 설정
field.setAccessible(true);
// 필드 값 설정
field.set(myClassInstance, "새로운 값");
// 필드 값 출력
System.out.println("Updated Field Value: " + field.get(myClassInstance));
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyClass {
private String privateField = "기본 값";
}
3. 메서드 호출
리플렉션을 사용하여 클래스의 메서드를 호출할 수 있습니다.
import java.lang.reflect.Method;
public class ReflectionExample {
public static void main(String[] args) {
try {
MyClass myClassInstance = new MyClass();
// 클래스 객체를 가져옴
Class<?> clazz = myClassInstance.getClass();
// 메서드 객체 가져오기
Method method = clazz.getDeclaredMethod("myMethod");
// 메서드 호출
method.invoke(myClassInstance);
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyClass {
private void myMethod() {
System.out.println("myMethod가 호출되었습니다.");
}
}
4. 생성자 호출
리플렉션을 사용하여 클래스의 생성자를 호출할 수 있습니다.
import java.lang.reflect.Constructor;
public class ReflectionExample {
public static void main(String[] args) {
try {
// 클래스 객체를 가져옴
Class<?> clazz = MyClass.class;
// 생성자 객체를 가져옴
Constructor<?> constructor = clazz.getDeclaredConstructor(String.class);
// 접근 가능하도록 설정
constructor.setAccessible(true);
// 생성자 호출
MyClass myClassInstance = (MyClass) constructor.newInstance("Hello Reflection!");
// 결과 출력
myClassInstance.displayMessage();
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyClass {
private String message;
public MyClass(String message) {
this.message = message;
}
public void displayMessage() {
System.out.println("Message: " + message);
}
}
작성하신 글에서 전반적인 내용은 맞지만, 몇 가지 표현을 개선하거나 정확히 해야 할 부분이 있습니다. 아래는 개선된 내용입니다:
기타 참고 사항
main 함수와 static 키워드
자바의 엔트리 포인트인 main 함수에 static 키워드가 붙어야 하는 이유는 클래스 로더가 런타임 데이터 영역에 코드를 로드할 때, 인스턴스가 생성되지 않은 MainClass를 실행할 수 없기 때문이다.
클래스는 인스턴스가 생성되면 힙(heap) 영역에 위치한다. 하지만 main 함수는 인스턴스 생성 전에 실행되어야 한다.
따라서 static으로 선언하여 메서드 영역(Method Area)에 위치하도록 하여, 인스턴스 생성 전에도 수행 가능하게 된다.
즉 static 키워드는 컴파일 시점에 값을 결정한다.
JVM의 Lazy Loading
JVM은 Lazy Loading 메커니즘을 사용한다. 클래스를 미리 메모리에 올리지 않고 그때마다 필요한 클래스를 메모리에 올려 효율적으로 관리한다.
final 키워드
자바의 final 키워드는 변경을 방지하는 데 사용되는 키워드이다. 클래스, 메서드, 변수에 사용할 수 있다.
-
클래스에 사용:
final클래스를 선언하면 해당 클래스를 상속할 수 없다. 예를 들어,public final class A {}로 선언된 클래스는 다른 클래스에서 확장할 수 없다. -
메서드에 사용:
final메서드를 선언하면 해당 메서드를 오버라이드할 수 없다. 예를 들어,public final void methodName() {}로 선언된 메서드는 서브클래스에서 재정의가 불가능하다. -
변수에 사용:
final변수를 선언하면 해당 변수는 한 번만 초기화될 수 있다. 초기화 이후 값을 변경할 수 없다. 예를 들어,final int number = 10;으로 선언된 변수는 이후 다른 값으로 수정할 수 없다.
인스턴스 변수일 경우 Heap, 지역 변수일 경우 Stack에 저장되며 객체 생성시 초기화된다.
final 키워드는 코드의 안정성과 불변성을 보장하는 데 도움을 준다.
불변객체
불변 객체는 객체 생성 이후 내부의 상태가 변하지 않는 객체이다.
- 필드가 원시 타입인 경우: final 키워드를 사용해 불변 객체를 만들 수 있다.
- 필드가 일반 객체 참조 변수인 경우: 객체를 사용하는 필드의 참조 변수도 불변 객체로 변경
- 필드가 배열, 리스트 등의 참조 변수인 경우: 생성시 새로운 List를 만들어 값을 복사하도록 해야한다. (깊은 복사를 방어적 복사(defensive-copy)라고한다.)
클래스의 초기화 시점에
-
클래스의 인스턴스 생성
-
클래스의 정적 메소드 호출
-
클래스의 정적 변수 값 할당 및 사용
Wrapper Class
Wrapper Class는 자바에서 기본 데이터 타입(Primitive Type)을 객체로 다루기 위해 제공하는 클래스이다. 자바는 객체 지향 언어이므로, 기본 타입을 객체로 변환해야 하는 경우가 발생하는데, 이때 Wrapper Class가 사용된다.
| 기본 타입 | Wrapper Class |
|---|---|
byte |
Byte |
short |
Short |
int |
Integer |
long |
Long |
float |
Float |
double |
Double |
char |
Character |
boolean |
Boolean |
박싱(Boxing)
박싱은 기본 데이터 타입(Primitive Type)을 Wrapper Class 객체로 변환하는 과정이다. 자바 5부터는 자동 박싱(Auto-Boxing)이 지원되어 개발자가 명시적으로 객체를 생성하지 않아도 자동으로 변환이 이루어진다.
int num = 10;
// 자동 박싱
Integer boxedNum = num; // 기본 타입 int가 Integer 객체로 변환
// 수동 박싱
Integer manualBoxing = Integer.valueOf(num);
언박싱(Unboxing)
언박싱은 Wrapper Class 객체를 기본 데이터 타입으로 변환하는 과정이다. 자바 5부터는 자동 언박싱(Auto-Unboxing)이 지원된다.
Integer boxedNum = 20;
// 자동 언박싱
int num = boxedNum; // Integer 객체가 기본 타입 int로 변환
// 수동 언박싱
int manualUnboxing = boxedNum.intValue();
박싱과 언박싱의 활용
Wrapper Class는 다음과 같은 경우에 유용하다:
- 컬렉션과의 호환성
자바 컬렉션 프레임워크(ArrayList,HashMap등)는 객체만 저장할 수 있으므로, 기본 타입은 Wrapper Class로 변환해야 한다.ArrayList<Integer> list = new ArrayList<>(); list.add(10); // 자동 박싱 int value = list.get(0); // 자동 언박싱 -
제네릭 타입 사용
제네릭 타입은 객체만을 처리할 수 있으므로 기본 타입을 사용할 수 없으며, Wrapper Class가 필요하다. - 유틸리티 메서드 활용
Wrapper Class는 기본 타입의 값을 변환하거나 비교하는 유틸리티 메서드(parseInt,valueOf등)를 제공한다.
제네릭(Generic)
Java의 제네릭은 클래스, 인터페이스, 메서드에서 사용할 데이터 타입을 컴파일 시점에 지정할 수 있도록 하는 기능이다. 제네릭을 사용하면 타입 안전성을 제공하며, 코드의 재사용성을 높일 수 있다. 제네릭을 사용함으로써 코드에서 발생할 수 있는 타입 오류를 컴파일 시점에 잡을 수 있어 실행 시 오류를 줄일 수 있다. (C++의 Template와 유사한 개념이다. 단 템플릿과 다르게 제네릭은 프리미티브 타입은 넣을 수 없다.)
사용법
제네릭은 클래스나 메서드를 선언할 때 타입 매개변수를 지정하는 방식으로 사용된다. 예를 들어, List<T>는 T라는 타입 매개변수를 가진 List 클래스를 의미한다. 이때 T는 실제 타입으로 교체될 수 있다.
예시:
class Box<T> {
private T item;
public void setItem(T item) {
this.item = item;
}
public T getItem() {
return item;
}
}
위 예시에서 Box<T>는 타입 파라미터 T를 사용하여 어떤 타입의 값을 담을 수 있는 클래스이다. 실제로 Box 객체를 만들 때는 T가 구체적인 타입으로 대체된다.
Box<String> stringBox = new Box<>();
stringBox.setItem("Hello");
String item = stringBox.getItem();
위 예시에서 Box<String>은 String 타입을 저장하는 박스가 된다.
제네릭의 장점
- 타입 안전성: 제네릭을 사용하면 컴파일 시점에 타입을 체크할 수 있기 때문에, 잘못된 타입을 사용할 경우 컴파일 오류가 발생한다. 이를 통해 런타임 오류를 줄일 수 있다.
- 코드 재사용성: 제네릭을 사용하면 다양한 타입에 대해 같은 로직을 처리할 수 있어, 중복 코드를 줄일 수 있다. 하나의 클래스를 여러 타입에 대해 사용할 수 있다.
- 타입 캐스팅을 피함: 제네릭을 사용하면 불필요한 타입 캐스팅을 피할 수 있다. 예를 들어,
List<Object>에서 값을 꺼낼 때, 제네릭을 사용하면 자동으로 올바른 타입으로 반환된다.
제네릭의 제한
- 프리미티브 타입 사용 불가: 제네릭은 프리미티브 타입(예:
int,char,double)을 사용할 수 없다. 대신, 래퍼 클래스(예:Integer,Character,Double)를 사용해야 한다. - 타입 소거: 제네릭은 컴파일 시점에만 타입 정보를 유지하고, 실행 시점에서는 타입 정보가 사라진다. 이를 타입 소거(type erasure)라고 한다. 예를 들어,
List<Integer>와List<String>은 실행 시점에서 동일한List타입으로 취급된다. -
불공변성: 타입안정성을 위한 설계 원칙으로, 제네릭 타입이 서로 다르다면 상속 관계와 무관하게 서로 다른 타입으로 취급한다.
List<Number> numberList = new ArrayList<>();List<Integer> integerList = new ArrayList<>();numberList = integerList // number는 integer의 상위타입이지만, 불공변적으로 서로 대입할 수 없다.
제네릭의 와일드카드
제네릭에서는 ?를 사용하여 불특정 타입을 나타낼 수 있다. 이를 와일드카드라고 한다. (불공변성을 유연하게 처리하기 위해 와일드카드를 사용할 수 있다.)
와일드카드는 ? extends T와 ? super T 두 가지로 사용할 수 있다.
? extends T:T의 자식 타입을 나타내며, 주로 상한 경계로 사용된다.? super T:T의 부모 타입을 나타내며, 주로 하한 경계로 사용된다.
제네릭의 와일드카드는 ? 기호를 사용하여 불특정 타입을 나타내는 방법이다. 와일드카드는 제네릭을 사용할 때 타입의 범위를 제한하거나, 유연성을 제공하기 위해 사용된다. 주로 ? extends T와 ? super T 두 가지 형태로 사용된다.
1. ? extends T (상한 경계, Upper Bound)
? extends T는 T의 자식 타입을 나타낸다. 즉, T 타입 또는 T의 자식 클래스들을 사용하려는 경우에 사용된다. 이 형태는 읽기 전용에 적합하다. 왜냐하면 자식 타입이 여러 개가 될 수 있기 때문에, 그 타입을 수정할 수 없고, T 또는 그 하위 타입을 읽기만 할 수 있게 된다.
List<? extends Number> list = new ArrayList<>();
list = new ArrayList<Integer>(); // OK
list = new ArrayList<Double>(); // OK
// list.add(10); // 컴파일 오류: add는 불가능
? extends Number는Number클래스와 그 자식 클래스들(Integer,Double등)을 모두 받을 수 있다.- 그러나
list.add()와 같은 쓰기 작업은 할 수 없다. 왜냐하면list가Integer,Double같은 여러 자식 타입을 가질 수 있기 때문에 정확히 어떤 타입이 들어갈지 알 수 없기 때문이다.
언제 사용하나?
- 상한 경계는 특정 타입을 읽을 때 사용하며, 해당 타입에 대해 수정 작업을 하지 않을 때 사용한다.
2. ? super T (하한 경계, Lower Bound)
? super T는 T 타입 또는 T의 부모 타입을 나타낸다. 이 형태는 쓰기 작업에 적합하다. 왜냐하면 부모 타입을 지정하면 T 타입과 그 자식 타입들을 모두 받을 수 있기 때문이다. 하지만 읽기 작업에 제한이 있다. ? super T를 사용하면 값을 꺼낼 때 정확한 타입을 알 수 없기 때문에 읽을 때는 Object로 취급된다.
List<? super Integer> list = new ArrayList<>();
list = new ArrayList<Number>(); // OK
list = new ArrayList<Object>(); // OK
list.add(10); // OK
// Integer num = list.get(0); // 컴파일 오류: 정확한 타입을 알 수 없음
? super Integer는Integer,Number,Object를 모두 받을 수 있다.list.add(10)은 정상적으로 작동한다. 왜냐하면Integer나 그 상위 타입이므로10을 추가할 수 있다.- 그러나 읽을 때는 정확한 타입을 알 수 없기 때문에
Object타입으로만 가져올 수 있다.
언제 사용하나?
- 하한 경계는 쓰기 작업을 할 때 사용되며, 해당 타입을 읽을 때는 일반적으로 Object로 읽게 된다.
3. 와일드카드를 사용하지 않으면
일반적으로 제네릭을 사용할 때, 구체적인 타입을 지정한다. 예를 들어, List<Integer>와 같이 지정한다. 하지만 와일드카드를 사용하면 특정 타입에 국한되지 않고 여러 타입을 유연하게 다룰 수 있다.
예시:
// 와일드카드를 사용하지 않은 경우
List<Integer> intList = new ArrayList<>();
List<Double> doubleList = new ArrayList<>();
// 와일드카드를 사용한 경우
List<?> list = new ArrayList<>();
list = new ArrayList<Integer>(); // OK
list = new ArrayList<Double>(); // OK